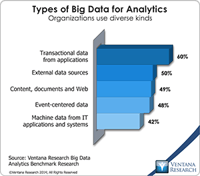
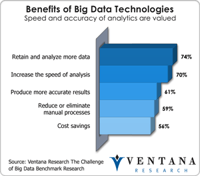
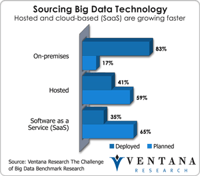
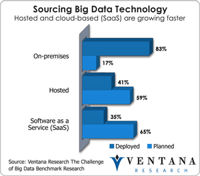
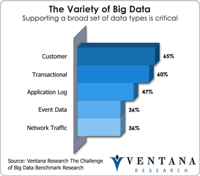
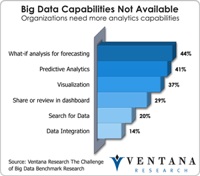
Big data has become a big deal as the technology industry has invested tens of billions of dollars to create the next generation of databases and data processing. After the accompanying flood of new categories and marketing terminology from vendors, most in the IT community are now beginning to understand the potential of big data. Ventana Research thoroughly covered the evolving state of the big data and information optimization sector in 2014 and will continue this research in 2015 and...
Read More
Topics:
Big Data,
MapR,
Predictive Analytics,
Sales Performance,
SAP,
Supply Chain Performance,
Human Capital,
Marketing,
Mulesoft,
Paxata,
SnapLogic,
Splunk,
Customer Performance,
Operational Performance,
Business Analytics,
Business Intelligence,
Business Performance,
Cloud Computing,
Cloudera,
Financial Performance,
Hortonworks,
IBM,
Informatica,
Information Management,
Operational Intelligence,
Oracle,
Datawatch,
Dell Boomi,
Information Optimization,
Savi,
Sumo Logic,
Tamr,
Trifacta,
Strata+Hadoop
SAS Institute, a long-established provider analytics software, showed off its latest technology innovations and product road maps at its recent analyst conference. In a very competitive market, SAS is not standing still, and executives showed progress on the goals introduced at last year’s conference, which I covered. SAS’s Visual Analytics software, integrated with an in-memory analytics engine called LASR, remains the company’s flagship product in its modernized portfolio. CEO Jim Goodnight...
Read More
Topics:
Predictive Analytics,
IT Performance,
LASR,
Operational Performance,
Analytics,
Business Analytics,
Business Intelligence,
Business Performance,
Cloudera,
Customer & Contact Center,
Hortonworks,
IBM,
Information Applications,
SAS institute,
Strata+Hadoop
I had the pleasure of attending Cloudera’s recent analyst summit. Presenters reviewed the work the company has done since its founding six years ago and outlined its plans to use Hadoop to further empower big data technology to support what I call information optimization. Cloudera’s executive team has the co-founders of Hadoop who worked at Facebook, Oracle and Yahoo when they developed and used Hadoop. Last year they brought in CEO Tom Reilly, who led successful organizations at ArcSight, HP...
Read More
Topics:
Big Data,
Teradata,
Zoomdata,
IT Performance,
Business Intelligence,
Cloudera,
Hortonworks,
IBM,
Information Applications,
Information Management,
Location Intelligence,
Operational Intelligence,
Oracle,
Hive,
Impala,
Strata+Hadoop
Organizations succeed through continuous planning to achieve high levels of performance. For most organizations planning is not an easy process to conduct. Planning software is typically designed for only a few people in the process, such as analysts, or organizations might use spreadsheets, which are not designed for business planning across an organization. Most technologies only allow you to examine the past and not plan for the future. For decades organizations have tried to focus planning...
Read More
Topics:
Big Data,
Sales Performance,
Supply Chain Performance,
Mobile Technology,
Operations,
Operational Performance,
Business Analytics,
Business Collaboration,
Business Intelligence,
Business Performance,
Cloud Computing,
Cloudera,
Customer & Contact Center,
Financial Performance,
Governance, Risk & Compliance (GRC),
Information Applications,
Workforce Performance,
Business Planning,
CFO,
finance,
Tidemark,
Workday
The big-data landscape just got a little more interesting with the release of EMC’s Pivotal HD distribution of Hadoop. Pivotal HD takes Apache Hadoop and extends it with a data loader and command center capabilities to configure, deploy, monitor and manage Hadoop. Pivotal HD, from EMC’s Pivotal Labs division, integrates with Greenplum Database, a massively parallel processing (MPP) database from EMC’s Greenplum division, and uses HDFS as the storage technology. The combination should help sites...
Read More
Topics:
EMC,
MapR,
HAWQ,
HDFS,
Pivotal HD,
Business Analytics,
Business Intelligence,
Cloud Computing,
Cloudera,
Hortonworks,
Information Applications,
Information Management,
Location Intelligence,
Cirro,
Hive,
Tableau Software,
Strata+Hadoop
SnapLogic, a provider of data integration in the cloud, this week announced Big Data-as-a-Service to address businesses’ needs to integrate and process data across Hadoop big data environments. As our research agenda for 2013 outlines, dealing with data in the cloud is very important to organizations. At the same time, businesses need to be able to integrate their big data with all their technology assets, as I pointed out recently.
Read More
Topics:
Big Data,
R,
Sales Performance,
Salesforce.com,
SnapLogic,
Operational Performance,
Business Analytics,
Cloud Computing,
Cloudera,
Customer & Contact Center,
Data Integration,
Information Applications,
Information Management
LucidWorks addresses the growing volume of information now being stored in the enterprise and in big data with two products aimed at the enterprise with search technology. Though you may not be familiar with LucidWorks (previously known as Lucid Imagination), the company has for many years contributed to Apache Lucene, an open source search project, and commercialized and supported for it for business.
Read More
Topics:
Big Data,
MapR,
Sales Performance,
IT Performance,
Operational Performance,
Business Analytics,
Business Intelligence,
Business Performance,
Cloud Computing,
Cloudera,
Customer & Contact Center,
Hortonworks,
Information Applications,
Information Management,
Operational Intelligence,
Search,
Strata+Hadoop
Actuate, the driving force behind the open source Eclipse Business Intelligence and Reporting Tools (BIRT) project, is positioning itself in the center of the big-data world through multiple partnerships with companies such as Cloudera, Hortonworks, KXEN, Pervasive and a number of OEMs. These agreements, following on its acquisition of Xenos a couple of years ago, help Actuate address some big issues in big data, involving enterprise integration and closed-loop operational systems that provide...
Read More
Topics:
Big Data,
Pervasive,
Eclipse,
IT Performance,
Operational Performance,
Analytics,
Business Analytics,
Business Collaboration,
Business Intelligence,
Business Performance,
Cloud Computing,
Cloudera,
Customer & Contact Center,
Information Applications,
Information Management,
Operational Intelligence,
Strata+Hadoop
As volumes of data grow in organizations, so do the number of deployments of Hadoop, and as Hadoop becomes widespread, more organizations demand data analysis, ease of use and visualization of large data sets. In our benchmark research on Hadoop, 88 percent of organizations said analyzing Hadoop data is important, and in our research on business analytics 89 percent said it is important to make it simpler to provide analytics and metrics to all users who need them. As my colleague Mark Smith...
Read More
Topics:
Big Data,
Datameer,
MapR,
Operational Performance,
Business Analytics,
Business Intelligence,
Business Performance,
Cloudera,
Customer & Contact Center,
Hortonworks,
IBM,
Information Applications,
Operational Intelligence,
Visualization,
Data Discovery,
Strata+Hadoop
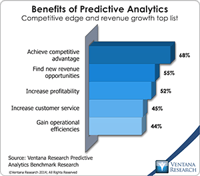
In our benchmark research in predictive analytics we’ve uncovered some intriguing tools for taking advantage of big data in the enterprise. Revolution Analytics, which we analyzed earlier this year, this month introduced its 6.0 release. Revolution extends the open source statistical programming language R with capabilities you would expect out of enterprise software. The company has grown substantially over the last several years and has an impressive list of more than a hundred customers in...
Read More
Topics:
Big Data,
Linux,
Predictive,
Revolution,
Operational Performance,
Business Analytics,
Business Intelligence,
Business Performance,
Cloud Computing,
Cloudera,
Data Mining,
Strata+Hadoop