
Cloudera provides database and enabling technology for the big data market and overall for data and information management. As my colleague David Menninger has written, the big data and information management technology markets are changing rapidly and require vendors to adapt to them. Cloudera has grown significantly over the last decade and now has approximately 1,000 customers and provides support and services in countries around the world. Its product and technology strategy is to provide a unified data management platform, Cloudera Enterprise, that can meet the data engineering and science needs for a range of analytic and operational database applications. Its primary focus is its Enterprise Data Hub, which as a data lake can handle organizations’ big data and analytical needs. As David Menninger asserts, the data lake is a safe way to invest in big data. It also helps shift the focus away from the V’s (volume, velocity and variety) of big data to the A’s, which are analytics, awareness, anticipation and action.
The latest public release of Cloudera Enterprise, version 5.10, in January includes Apache Kudu for real-time analytics improves performance of Apache Hive and auditing and lineages with Cloudera Navigator for Amazon S3. Last fall Cloudera donated Apache Kudu technology to the Apache Software Foundation so that this high-performance columnar store for Hadoop can provide better access to streaming data for all in the Apache community. The 5.10 release notes provide more details on Cloudera Navigator and other improvements.
Cloudera acknowledges the importance of providing tools to help data scientists use its platform in the recent announcement of its Cloudera Data Science Workbench, a tool which can use R, Python or Scala language to create direct access to Hadoop clusters with Apache Spark and Impala. The Workbench tool competes with a dozen or so other data science tools in the market from IBM, RapidMiner, SAS and others, many of which are Cloudera partners. These types of tools help make Hadoop successful, as David Menninger wrote about discussing the Hadoop ecosystem and ongoing changes in the database markets. As he pointed out in another perspective, though, the community of technologies that let Hadoop operate in a production environment consists of more than just one vendor. Our big data integration research, finds data quality (52%) 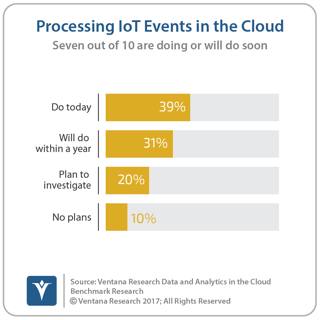 and preparation (46%) to be the largest two issues, a gap that Cloudera is addressing by working with partners such as Trifacta, which was at the analyst summit showing its support.
and preparation (46%) to be the largest two issues, a gap that Cloudera is addressing by working with partners such as Trifacta, which was at the analyst summit showing its support.
Cloudera has been rapidly advancing in efforts on big data and cloud computing in recent years in order to make its products readily available through cloud environments. In the process, it must deal with competitive big data approaches by each of the major cloud computing platforms, which include Amazon Web Services, Google Compute and Microsoft Azure. Cloudera treats this competition as an opportunity to provide its big data technology across these platforms, giving organizations consistency and flexibility. Cloudera’s move to directly support cloud computing will coincide with significantly more opportunity in supporting the range of technology use cases. For example, our benchmark research on the Data and Analytics in the Cloud finds more than half of organizations (51%) planning to process IoT events in the cloud in the next year or planning to do, in addition to the substantial number already doing that.
Cloudera presented five major areas in which it is advancing use of its products: customer 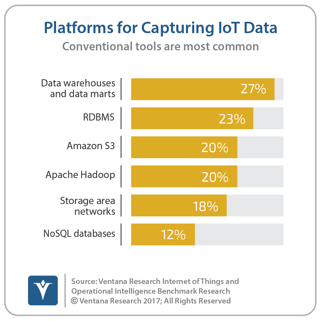 insights, IoT, secure business, machine learning and cloud computing. For the first, it is important for Cloudera to advance awareness that Apache Hadoop can support IoT; our benchmark research on IoT finds that it is being considered in one-fifth of organizations but not in as much use as data warehouses or RDBMSs and is challenged by even Amazon S3. We see a focus on customer insights as critical to business use of big data, particularly through improving customer engagement and experience processes. In this area Cloudera is focused on data analytics that can be presented through the software of its partners such as Datameer, Qlik, SAS, Tableau and Zoomdata. However, our research finds the largest challenge is ingestion of conversational data like speech and voice, which, along with chat and text data, are typically sourced from other providers such Genesys, NICE and Verint and others that offer omnichannel contact center solutions that has not partnered with yet.
insights, IoT, secure business, machine learning and cloud computing. For the first, it is important for Cloudera to advance awareness that Apache Hadoop can support IoT; our benchmark research on IoT finds that it is being considered in one-fifth of organizations but not in as much use as data warehouses or RDBMSs and is challenged by even Amazon S3. We see a focus on customer insights as critical to business use of big data, particularly through improving customer engagement and experience processes. In this area Cloudera is focused on data analytics that can be presented through the software of its partners such as Datameer, Qlik, SAS, Tableau and Zoomdata. However, our research finds the largest challenge is ingestion of conversational data like speech and voice, which, along with chat and text data, are typically sourced from other providers such Genesys, NICE and Verint and others that offer omnichannel contact center solutions that has not partnered with yet.
Cloudera is now providing focused examples of use of its products through its Solutions Gallery, which includes a section that highlights machine learning, including examples from RapidMiner and Rocana. Cloudera also highlighted ADP for embedding Cloudera in its ADP DataCloud, which offers exploratory analytics of human capital management data and was recognized by us as a Technology Innovation Award winner in 2016.
Cloudera emphasized its partnership with Intel and the significant investment the two have made, but at the summit no one offered specifics on how this investment has materialized. Cloudera has placed case studies online involving the use of Intel Xeon processors, which many database providers could point to as well, but it is not yet clear how the partnership will evolve. This investment helps keep Intel in the discussion of advances in processing and chip technologies.
I found it interesting that Cloudera has ramped up its competitive posturing where top rival IBM is concerned, offering the brash commentary that IBM Watson is just a brand marketing initiative; however, our firm and others have assessed IBM’s efforts and know it has a major R&D focus on its Watson platform. Cloudera would do best to leave market analysis to the analysts or do more homework on IBM’s efforts in cognitive computing, machine learning, IBM Data Science Experience and related products. Even those who do not analyze the company’s products and direction continuously can find these sites on the Internet within seconds. Cloudera should worry less about IBM and its views, where I found less-than-accurate representation, and invest more in education on its differentiation across its use cases, which are not yet fully exploited on its website.
At the core of Cloudera is its continued support of the Apache Hadoop movement, which is positioned at the center of big data technological advances and will continue to be a force in data management and within the developer community. Cloudera is a key market player in Apache Hadoop, involving production and high-scale efforts that, for many projects, are part of its value. For example, Apache Spark is an integrated distribution with Cloudera Enterprise for in-memory data processes for batch and real-time processing for advanced analytics. Apache Kafka is a distribution that supports large-scale message processing with partitioning, replication and fault tolerance. Apache Kudu provides storage along with fast inserts and updates alongside efficient columnar scans to enable multiple real-time analytic workloads across a single storage layer.
Cloudera is a critical provider of big data technology for anyone looking at large-scale big data processing to support its operations and analytics. Since my first coverage of Cloudera in 2010 the company has come a long way and, even since my 2014 analysis, has been accelerating its growth among customers and partners. If you are looking to advance new efforts or retrofit existing ones for on-premises and cloud computing for any sort of data management, you should be considering Cloudera.
Regards,
Mark
Mark Smith
CEO and Chief Research Officer
Authors:

Mark Smith
Partner, Head of Software Research
Mark Smith is the Partner, Head of Software Research at ISG and Ventana Research leading the global market agenda as a subject matter expert in digital business and enterprise software. Mark is a digital technology enthusiast using market research and insights to educate and inspire enterprises, software and service providers.








