
I recently wrote about the need for organizations to take a holistic approach to the management and governance of data in motion alongside data at rest. As adoption of streaming data and event processing increases, it is no longer sufficient for streaming data projects to exist in isolation. Data needs to be managed and governed regardless of whether it is processed in batch or as a stream of events. This requirement has resulted in established data management vendors increasing their focus on streaming data and event processing through product development as well as acquisitions. It has also resulted in streaming and event specialists, such as Confluent, adding centralized management and governance capabilities to their existing offerings as they seek to establish or reinforce the strategic importance of streaming data as part of a modern approach to data management.
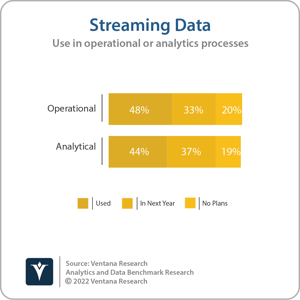 Confluent was founded in 2014 by the founders of the Apache Kafka distributed event streaming project, which was originally developed at LinkedIn to store and process data related to member activity, as well as logs and metrics. Confluent initially introduced Confluent Platform, its commercially supported distribution, to facilitate adoption of Apache Kafka by organizations, both on-premises and on public cloud infrastructure. That was followed in 2017 by the general availability of its Confluent Cloud managed service. Revenue from Confluent Cloud grew 200% in Confluent’s fiscal year 2021 to reach $94 million. Total revenue grew 64% to $388 million in the same period, illustrating that while many Confluent customers are transitioning to the managed cloud service, a substantial proportion of Confluent business is still driven by on-premises deployments. The company, which completed its initial public offering on Nasdaq in July 2021, has expanded its revenue thanks to growing adoption of streaming data and event processing. Almost one-half of respondents (48%) to Ventana Research’s Analytics and Data Benchmark Research work at organizations that use streaming data in operational processes, while 44% use streaming data in analytics processes. Confluent has also fueled adoption through the expansion of functionality available in Confluent Platform and Confluent Cloud above and beyond the core capabilities of Apache Kafka. Differentiating functionality addresses requirements such as cluster management and monitoring, SQL-based streaming analytics, security, data governance, resiliency, developer productivity, and cloud-native architecture. Companies use Confluent’s software to support a range of use cases including customer engagement and experience, cybersecurity, real-time and predictive analytics, and logistics and internet of things (IoT) management. Customers include the likes of AO, Sainsbury’s and Dick’s Sporting Goods in retail, and Citigroup, Euronext and RBC in financial services, with other key industries including automotive, gaming, manufacturing and insurance.
Confluent was founded in 2014 by the founders of the Apache Kafka distributed event streaming project, which was originally developed at LinkedIn to store and process data related to member activity, as well as logs and metrics. Confluent initially introduced Confluent Platform, its commercially supported distribution, to facilitate adoption of Apache Kafka by organizations, both on-premises and on public cloud infrastructure. That was followed in 2017 by the general availability of its Confluent Cloud managed service. Revenue from Confluent Cloud grew 200% in Confluent’s fiscal year 2021 to reach $94 million. Total revenue grew 64% to $388 million in the same period, illustrating that while many Confluent customers are transitioning to the managed cloud service, a substantial proportion of Confluent business is still driven by on-premises deployments. The company, which completed its initial public offering on Nasdaq in July 2021, has expanded its revenue thanks to growing adoption of streaming data and event processing. Almost one-half of respondents (48%) to Ventana Research’s Analytics and Data Benchmark Research work at organizations that use streaming data in operational processes, while 44% use streaming data in analytics processes. Confluent has also fueled adoption through the expansion of functionality available in Confluent Platform and Confluent Cloud above and beyond the core capabilities of Apache Kafka. Differentiating functionality addresses requirements such as cluster management and monitoring, SQL-based streaming analytics, security, data governance, resiliency, developer productivity, and cloud-native architecture. Companies use Confluent’s software to support a range of use cases including customer engagement and experience, cybersecurity, real-time and predictive analytics, and logistics and internet of things (IoT) management. Customers include the likes of AO, Sainsbury’s and Dick’s Sporting Goods in retail, and Citigroup, Euronext and RBC in financial services, with other key industries including automotive, gaming, manufacturing and insurance.
%20(1)-png-2.png?width=300&name=VR_2022_Streaming_Data_and_Events_Assertion_1_Square%20(1)%20(1)-png-2.png) The use of streaming data and event processing is becoming more mainstream. I assert that by 2024, more than one-half of all organizations’ standard information architectures will include streaming data and event processing, allowing organizations to be more responsive and provide better customer experiences. Functionality to address the needs of people with a variety of skill sets in multiple roles is important to enable and fuel this adoption. Early deployments of Apache Kafka were dependent on highly skilled, streaming data specialists who were able to design, deploy and maintain streaming data pipelines and the associated infrastructure. Confluent recognized that while the publish-and-subscribe messaging and event processing capabilities of Apache Kafka were important for supporting distributed data processing, they were not enough — particularly as organizations moved away from a focus on sequential data processing to the continuous processing of data flows — and that there was also a requirement to lower the expertise barriers to adopting and managing stream-processing architecture. Although Confluent Platform is based on Apache Kafka, it has been re-achitectured in recent years via Confluent for Kubernetes, which was developed based on Confluent’s experience of delivering the Confluent Cloud managed service, to provide a cloud-native experience on-premises. Confluent Platform and Confluent Cloud feature capabilities targeted at developers, operators and architects. Developer-oriented capabilities include support for multiple development languages and tools; a library of over 120 prebuilt Kafka connectors; Schema Registry for schema management; a RESTful HTTP service; and the ksqlDB streaming SQL engine. Functionality aimed at operators includes the Control Center user interface for managing and monitoring Apache Kafka; support for Kubernetes and automated deployment using Ansible and HashiCorp; and support for tiered storage and automated data and cluster rebalancing. Architects are served by security features including at-rest encryption of configuration files, audit logs and role-based access control; schema management (using Schema Registry) and programmatic schema validation; and support for global availability via multi-region clusters for disaster recovery, Kafka topic replication, and Cluster Linking to connect on-premises and cloud environments for multi-data center, multi-region, and hybrid cloud deployments. A major focus of Confluent’s recent research and development has been data governance as evidenced by the general availablility of its Stream Governance suite in September 2021, building on Schema Registry to provide streaming data quality, lineage and self-service data discovery via stream catalog. In addition to these capabilities, Confluent Cloud provides automated and managed cluster configuration, deployment, management, monitoring and administration, and is available as a managed service on Amazon Web Services, Microsoft Azure and Google Cloud.
The use of streaming data and event processing is becoming more mainstream. I assert that by 2024, more than one-half of all organizations’ standard information architectures will include streaming data and event processing, allowing organizations to be more responsive and provide better customer experiences. Functionality to address the needs of people with a variety of skill sets in multiple roles is important to enable and fuel this adoption. Early deployments of Apache Kafka were dependent on highly skilled, streaming data specialists who were able to design, deploy and maintain streaming data pipelines and the associated infrastructure. Confluent recognized that while the publish-and-subscribe messaging and event processing capabilities of Apache Kafka were important for supporting distributed data processing, they were not enough — particularly as organizations moved away from a focus on sequential data processing to the continuous processing of data flows — and that there was also a requirement to lower the expertise barriers to adopting and managing stream-processing architecture. Although Confluent Platform is based on Apache Kafka, it has been re-achitectured in recent years via Confluent for Kubernetes, which was developed based on Confluent’s experience of delivering the Confluent Cloud managed service, to provide a cloud-native experience on-premises. Confluent Platform and Confluent Cloud feature capabilities targeted at developers, operators and architects. Developer-oriented capabilities include support for multiple development languages and tools; a library of over 120 prebuilt Kafka connectors; Schema Registry for schema management; a RESTful HTTP service; and the ksqlDB streaming SQL engine. Functionality aimed at operators includes the Control Center user interface for managing and monitoring Apache Kafka; support for Kubernetes and automated deployment using Ansible and HashiCorp; and support for tiered storage and automated data and cluster rebalancing. Architects are served by security features including at-rest encryption of configuration files, audit logs and role-based access control; schema management (using Schema Registry) and programmatic schema validation; and support for global availability via multi-region clusters for disaster recovery, Kafka topic replication, and Cluster Linking to connect on-premises and cloud environments for multi-data center, multi-region, and hybrid cloud deployments. A major focus of Confluent’s recent research and development has been data governance as evidenced by the general availablility of its Stream Governance suite in September 2021, building on Schema Registry to provide streaming data quality, lineage and self-service data discovery via stream catalog. In addition to these capabilities, Confluent Cloud provides automated and managed cluster configuration, deployment, management, monitoring and administration, and is available as a managed service on Amazon Web Services, Microsoft Azure and Google Cloud.
I recently recommended that all organizations that have not already done so should investigate the potential opportunities for streaming data and analytics in their organization, while those that have already adopted streaming data for niche workloads examine the potential for a more holistic approach to managing and governing data in motion and data at rest. Confluent has built on its expertise with Apache Kafka to establish a broad portfolio of capabilities for managing data in motion. While capabilities that support the holistic management and governance of data in motion and data at rest are emerging, any organizations considering establishing or expanding an investment in streaming data and event processing should include Confluent in their evaluations.
Regards,
Matt Aslett
Authors:

Matt Aslett
Director of Research, Analytics and Data
Matt Aslett leads the software research and advisory for Analytics and Data at Ventana Research, now part of ISG, covering software that improves the utilization and value of information. His focus areas of expertise and market coverage include analytics, data intelligence, data operations, data platforms, and streaming and events.








