
The concept and implementation of what is called big data are no longer new, and many organizations, especially larger ones, view it as a way to manage and understand the flood of data they receive. Our benchmark research on big data analytics shows that business intelligence (BI) is the most common type of system to which organizations deliver big data. However, BI systems aren’t a good fit for analyzing big data. They were built to provide interactive analysis of structured data sources using Structured Query Language (SQL). Big data includes large volumes of data that does not fit into rows and columns, such as sensor data, text data and Web log data. Such data must be transformed and modeled before it can fit into paradigms such as SQL.
The result is that currently many organizations run separate systems for big data and business intelligence. On one system, conventional BI tools as well as new visual discovery tools act on structured data sources to do fast interactive analysis. In this area analytic databases can use column store approaches and visualization tools as a front end for fast interaction with the data. On other systems, big data is stored in distributed systems such as the Hadoop Distributed File System (HDFS). Tools that use it have been developed to access, process and analyze the data. Commercial distribution companies aligned with the open source Apache Foundation, such as Cloudera, Hortonworks and MapR, have built ecosystems around the MapReduce processing paradigm. MapReduce works well for search-based tasks but not so well for the interactive analytics for which business intelligence systems are known. This situation has created a divide between business technology users, who gravitate to visual discovery tools that provide easily accessible and interactive data exploration, and more technically skilled users of big data tools that require sophisticated access paradigms and elongated query cycles to explore data.
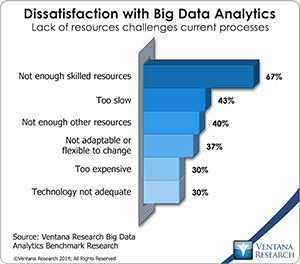 There are two challenges with the MapReduce approach. First, working with it is a highly technical endeavor that requires advanced skills. Our big data analytics research shows that lack of skills is the most widespread reason for dissatisfaction with big data analytics, mentioned by more than two-thirds of companies. To fill this gap, vendors of big data technologies should facilitate use of familiar interfaces including query interfaces and programming language interfaces. For example, our research shows that Standard SQL is the most important method for implementing analysis on Hadoop. To deal with this challenge, the distribution companies and others offer SQL abstraction layers on top of HDFS, such as HIVE and Cloudera Impala. Companies that I have written about include Datameer and Platfora, whose systems help users interact with Hadoop data via interactive systems such as spreadsheets and multidimensional cubes. With their familiar interaction paradigms such systems have helped increase adoption of Hadoop and enable more than a few experts to access big data systems.
There are two challenges with the MapReduce approach. First, working with it is a highly technical endeavor that requires advanced skills. Our big data analytics research shows that lack of skills is the most widespread reason for dissatisfaction with big data analytics, mentioned by more than two-thirds of companies. To fill this gap, vendors of big data technologies should facilitate use of familiar interfaces including query interfaces and programming language interfaces. For example, our research shows that Standard SQL is the most important method for implementing analysis on Hadoop. To deal with this challenge, the distribution companies and others offer SQL abstraction layers on top of HDFS, such as HIVE and Cloudera Impala. Companies that I have written about include Datameer and Platfora, whose systems help users interact with Hadoop data via interactive systems such as spreadsheets and multidimensional cubes. With their familiar interaction paradigms such systems have helped increase adoption of Hadoop and enable more than a few experts to access big data systems.
The second challenge is latency. As a batch process MapReduce must sort and aggregate all of the data before creating analytic output. Technology such as Tez, developed by Hortonworks, and Cloudera Impala aim to address such speed limitations; the first leverages MapReduce, and the other circumvents MapReduce altogether. Adoption of these tools has moved the big data market forward, but challenges remain such as the continuing fragmentation of the Hadoop ecosystem and a lack of standardization in approaches.
An emerging technology holds promise for bridging the gap between big data and BI in a way that can unify big data ecosystems rather than dividing them. Apache Spark, under development since 2010 at the University of California Berkeley’s AMPLab, addresses both usability and performance concerns for big data. It adds flexibility by running on multiple platforms in terms of both clustering (such as Hadoop YARN and Apache Mesos) and distributed storage (for example, HDFS, Cassandra, Amazon S3 and OpenStack’s Swift). Spark also expands the potential uses because the platform includes an SQL abstraction layer (Spark SQL), a machine learning library (MLlib), a graph library (GraphX) and a near-real-time engine (Spark Streaming). Furthermore, Spark can be programmed using modern languages such as Python and Scala. Having all of these components integrated is important because interactive business intelligence, advanced analytics and operational intelligence on big data all can work without dealing with the complexity of having individual proprietary systems that were necessary to do the same things previously.
Because of this potential Spark is becoming a rallying point for providers of big data analytics. It has become the most active Apache project as key open source contributors moved their focus from other Hadoop projects to it. Out of the effort in Berkeley, Databricks was founded for commercial development of open source Apache Spark and has raised more than $46 million. Since the initial release in May 2014 the momentum for Spark has continued to build; major companies have made announcements around Apache Spark. IBM said it will dedicate 3,500 researchers and engineers to develop the platform and help customers deploy it. This is the largest dedicated Spark effort in the industry, akin to the move IBM made in the late 1990s with the Linux open source operating system. Oracle has built Spark into its Big Data Appliance. Microsoft has Spark as an option on its HDInsight big data approach but has also announced Prajna, an alternative approach to Spark. SAP has announced integration with its SAP HANA platform, although it represents “coopetition” for SAP’s in-memory platform. In addition, all the major business intelligence players have built or are building connectors to run on Spark. In time, Spark likely will serve as a data ingestion engine for connecting devices in the Internet of Things (IoT). For instance, Spark can integrate with technologies such as Apache Kafka or Amazon Kinesis to instantly process and analyze IoT data so that immediate action can be taken. In this way, as it is envisioned by its creators, Spark can serve as the nexus of multiple systems.
Because it is a flexible in-memory technology for big data, Spark opens the door to many new opportunities, which in business use include interactive analysis, advanced customer analytics, fraud detection, and systems and network management. At the same time, it is not yet a mature technology and for this reason, organizations considering adoption should tread carefully. While Spark may offer better performance and usability, MapReduce is already widely deployed. For those users, it is likely best to maintain the current approach and not fix what is not broken. For future big data use, however, Spark should be carefully compared to other big data technologies. In this case as well as others, technical skills can still be a concern. Scala, for instance, one of the key languages used with Spark, has little adoption, according to our recent research on next-generation predictive analytics. Manageability is an issue as for any other nascent technology and should be carefully addressed up front. While, as noted, vendor support for Spark is becoming apparent, frequent updates to the platform can mean disruption to systems and processes, so examine the processes for these updates. Be sure that vendor support is tied to meaningful business objectives and outcomes. Spark is an exciting new technology, and for early adopters that wish to move forward with it today, both big opportunities and challenges are in store.
fraud detection, and systems and network management. At the same time, it is not yet a mature technology and for this reason, organizations considering adoption should tread carefully. While Spark may offer better performance and usability, MapReduce is already widely deployed. For those users, it is likely best to maintain the current approach and not fix what is not broken. For future big data use, however, Spark should be carefully compared to other big data technologies. In this case as well as others, technical skills can still be a concern. Scala, for instance, one of the key languages used with Spark, has little adoption, according to our recent research on next-generation predictive analytics. Manageability is an issue as for any other nascent technology and should be carefully addressed up front. While, as noted, vendor support for Spark is becoming apparent, frequent updates to the platform can mean disruption to systems and processes, so examine the processes for these updates. Be sure that vendor support is tied to meaningful business objectives and outcomes. Spark is an exciting new technology, and for early adopters that wish to move forward with it today, both big opportunities and challenges are in store.
Regards,
Tony Cosentino
VP and Research Director
Authors:
Ventana Research
Ventana Research, now part of Information Services Group (ISG), is the most authoritative and respected market research and advisory services firm focused on improving business outcomes through optimal use of people, processes, information and technology. Since our beginning, our goal has been to provide insight and expert guidance on mainstream and disruptive technologies. In short, we want to help you become smarter and find the most relevant technology to accelerate your organization's goals.








