
The challenge with discussing big data analytics is in cutting through the ambiguity that surrounds the term. People often focus on the 3 Vs of big data – volume, variety and velocity – which provides a good lens for big data technology, but only gets us part of the way to understanding big data analytics, and provides even less guidance on how to take advantage of big data analytics to unlock business value.
Part of the challenge of defining big data analytics is a lack of clarity 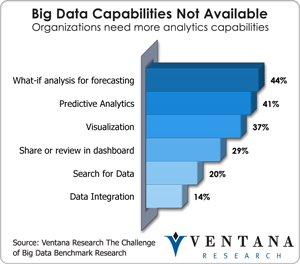 around the big data analytics value chain – from data sources, to analytic scalability, to analytic processes and access methods. Our recent research on big data find many capabilities still not available including predictive analytics (41%) to visualization (37%). Moreover, organizations are unclear on how best to initiate changes in the way they approach data analysis to take advantage of big data and what processes and technologies they ought to be using. The growth in use of appliances, Hadoop and in-memory databases and the growing footprints of RDBMSes all add up to pressure to have more intelligent analytics, but the most direct and cost-effective path from here to there is unclear. What is certain is that as business analytics and big data increasingly merge, the potential for increased value is building expectations.
around the big data analytics value chain – from data sources, to analytic scalability, to analytic processes and access methods. Our recent research on big data find many capabilities still not available including predictive analytics (41%) to visualization (37%). Moreover, organizations are unclear on how best to initiate changes in the way they approach data analysis to take advantage of big data and what processes and technologies they ought to be using. The growth in use of appliances, Hadoop and in-memory databases and the growing footprints of RDBMSes all add up to pressure to have more intelligent analytics, but the most direct and cost-effective path from here to there is unclear. What is certain is that as business analytics and big data increasingly merge, the potential for increased value is building expectations.
To understand the organizational chasm that exists with respect to big data analytics, it’s important to understand two foundational analytic approaches that are used in organizations today. Former Census Bureau Director Robert Grove’s ideas around designed data and organic data give us a great jumping off point for this discussion, especially as it relates to big data analytics.
In Grove’s estimation, the 20th century was about designed data, or what might be considered hypothesis-driven data. With designed data we engage in analytics by establishing a hypothesis and collecting data to prove or disprove it. Designed data is at the heart of confirmatory analytics, where we go out and collect data that are relevant to the assumptions we have already made. Designed data is often considered the domain of the statistician, but it is also at the heart of structured databases, since we assume that all of our data can fit into columns and rows and be modeled in a relational manner.
In contrast to the designed data approach of the 20th century, the 21st century is about organic data. Organic data is data that is not limited by a specific frame of reference that we apply to it, and because of this it grows without limits and without any structure other than that structure provided by randomness and probability. Organic data represents all data in the world, but for pragmatic reasons we may think of it as all the data we are able to instrument. RFID, GPS data, sensor data, sentiment data and various types of machine data are all organic data sources that may be characterized by context or by attributes such data sparsity (also known as low-density data). Much like the interpretation of silence in a conversation, analyzing big data is as much about interpreting that which exists between the lines as it is about what we can put on the line itself.
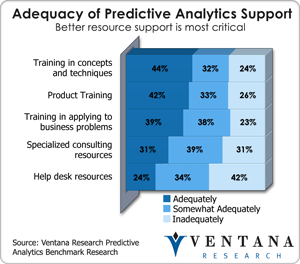 These two types of data and the analytics associated with them reveal the chasm that exists within organizations and shed light on the skills gap that our predictive analytics benchmark research shows to be the primary challenge for analytics in organizations today. This research finds inadequate support in many areas including product training (26%) and how to apply to business problems (23%). On one side of the chasm are the business groups and the analysts who are aligned with Grove’s idea of designed data. These groups may encompass domain experts in areas such as finance or marketing, advanced Excel, and even Ph.D.-level statisticians. These analysts serve organizational decision-makers and tied closely to actionable insights that lead to specific business outcomes. The way they get work done is through a flat file environment, as was outlined in some detail last week by my colleague Mark Smith. In this environment, Excel is often the lowest common denominator.
These two types of data and the analytics associated with them reveal the chasm that exists within organizations and shed light on the skills gap that our predictive analytics benchmark research shows to be the primary challenge for analytics in organizations today. This research finds inadequate support in many areas including product training (26%) and how to apply to business problems (23%). On one side of the chasm are the business groups and the analysts who are aligned with Grove’s idea of designed data. These groups may encompass domain experts in areas such as finance or marketing, advanced Excel, and even Ph.D.-level statisticians. These analysts serve organizational decision-makers and tied closely to actionable insights that lead to specific business outcomes. The way they get work done is through a flat file environment, as was outlined in some detail last week by my colleague Mark Smith. In this environment, Excel is often the lowest common denominator.
On the other side of the chasm exist the IT and database professionals, where a different analytical culture and mindset exist. The priority challenge for this group is dealing with the three Vs and simply organizing data into a legitimate enterprise data set. This group is often more comfortable with large data sets and machine learning approaches that are the hallmark of the organic data of 21st century. Their analytical environment is different from that of their business counterparts; rather than Excel, it is SQL that is often the lowest common denominator.
As I wrote in a recent blog post, database professionals and business analytics practitioners have long lived in parallel universes. In technology, practitioners deal with tables, joins and the ETL process. In business analysis, practitioners deal with datasets, merges and data preparation. When you think about it, these are the same things. The subtle difference is that database professionals have had a data mining mindset, or, as Grove calls it, an organic data mindset, while the business analyst has had a designed data or statistic-driven mindset. The bigger differences revolve around the cultural mindset, and the tools that are used to carry out the analytical objectives. These differences represent the current conundrum for organizations.
In a world of big data analytics, these two sides of the chasm are being pushed together in a shotgun wedding because the marriage of these groups is how competitive advantage is achieved. Both groups have critical contributions to make, but need to figure out how to work together before they can truly realize the benefits of big data analytics. The firms that understand that the merging of these different analytical cultures is the primary challenge facing the analytics organization, and that develop approaches that deal with this challenge, will take the lead in big data analytics. We already see this as a primary focus area for leading professional services organizations.
In my next analyst perspective on big data I will lay out some pragmatic approaches companies are using to address this big data analytics chasm, which represent the focus of the benchmark research we’re currently designing to understand organizational best practices in big data analytics as part of my research agenda.
Regards,
Tony Cosentino
VP and Research Director
Authors:
Ventana Research
Ventana Research, now part of Information Services Group (ISG), is the most authoritative and respected market research and advisory services firm focused on improving business outcomes through optimal use of people, processes, information and technology. Since our beginning, our goal has been to provide insight and expert guidance on mainstream and disruptive technologies. In short, we want to help you become smarter and find the most relevant technology to accelerate your organization's goals.








