
The data catalog has become an integral component of organizational data strategies over the past decade, serving as a conduit for good data governance and facilitating self-service analytics initiatives. The data catalog has become so important, in fact, that it is easy to forget that just 10 years ago it did not exist in terms of a standalone product category. Metadata-based data management functionality has had a role to play within products for data governance and business intelligence for much longer than that, of course, but the emergence of the data catalog as a product category provided a platform for metadata-based data inventory and discovery that could span an entire organization, serving multiple departments, use cases and initiatives.
-png.png?width=300&name=VR_2022_Data_Governance_Assertion_2_Square%20(1)-png.png) Data catalogs support the requirements of data operators, with capabilities to address internal data governance policies as well as external regulatory requirements. Data catalogs also support the requirements of data consumers with functionality to address self-service data discovery and collaboration. Both are supported by automation, with data catalogs using artificial intelligence and machine learning to accelerate metadata collection, semantic inference and tagging as well as recommendations.
Data catalogs support the requirements of data operators, with capabilities to address internal data governance policies as well as external regulatory requirements. Data catalogs also support the requirements of data consumers with functionality to address self-service data discovery and collaboration. Both are supported by automation, with data catalogs using artificial intelligence and machine learning to accelerate metadata collection, semantic inference and tagging as well as recommendations.
Initial adoption of data catalog products was led by large organizations embarking on digital transformation and data governance modernization initiatives and digital native startups recognizing the importance of data democratization to creating a data-driven culture. Adoption has now spread to organizations of all shapes and sizes. I assert that through 2024, 7 in ten organizations will use data catalog technologies to improve data governance and accelerate data-driven decision-making.
The results of Ventana Research’s Data Governance Benchmark Research illustrate the significance of the data catalog to data governance initiatives. Almost nine in 10 (89%) respondents stated that a data catalog with search capabilities is important for data governance, while four-fifths (80%) are using a data catalog as part of data governance efforts. Almost one-half (47%) of participants are using a data catalog at least once a day.
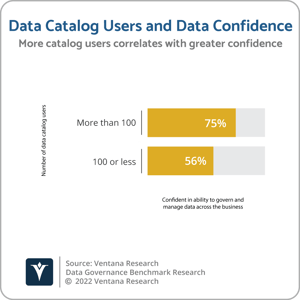
The research also indicates that, the more data catalog users an organization has, the greater the trust the organization has in its data and the higher the level of confidence in the organization’s ability to govern and manage data across the business. Almost three-quarters (74%) of organizations with more than 100 data catalog users have trust in the data used in decision-making and operations, compared to 66% of those with 100 or less data catalog users. Similarly, three-quarters (75%) of organizations with more than 100 data catalog users are confident in the organization’s ability to govern and manage data across the business, compared to 56% of organizations with 100 or less data catalog users.
 Adoption of data catalogs has also been driven by the role they play in enabling organizations to inventory and discover data in data lake environments, which have also evolved in the past 10 years to provide organizations with new approaches to storing and analyzing large volumes of data from multiple applications to generate business insight. Initially based primarily on Apache Hadoop, data lakes are today increasingly based on cloud object storage and are a relatively inexpensive way of storing large volumes of data, including structured data as well as semi-structured and unstructured data that is unsuitable for storing and processing in a data warehouse. Additional functionality is required to ensure that all that data is useful from a business context.
Adoption of data catalogs has also been driven by the role they play in enabling organizations to inventory and discover data in data lake environments, which have also evolved in the past 10 years to provide organizations with new approaches to storing and analyzing large volumes of data from multiple applications to generate business insight. Initially based primarily on Apache Hadoop, data lakes are today increasingly based on cloud object storage and are a relatively inexpensive way of storing large volumes of data, including structured data as well as semi-structured and unstructured data that is unsuitable for storing and processing in a data warehouse. Additional functionality is required to ensure that all that data is useful from a business context.
Ventana Research’s Data Lake Dynamic Insight research found that almost all data lake adopters (97%) use or plan to use additional technologies to help manage and govern data lake environments. The most popular, used by almost one-half (46%) of organizations, is the data catalog, followed by open-source data management projects and custom code and scripts (both 39%), data governance products (29%) and data management products (28%). Use of these technologies is higher among organizations that have been in production with data lake environments for longer. For example, among those that have had a data lake deployed for more than two years, more than one-half (51%) are using a data catalog.
The importance of the data catalog for providing an inventory of data in a data lake is highlighted by the complexity involved in using a data lake to store and process large volumes of raw data from multiple operational applications in a variety of formats to be queried by multiple business departments for diverse analytic workloads. More than one-half of organizations use a data lake to store data from three or more operational data sources, and more than one-half store data using two or more file formats. More than two-thirds are running two or more analytics workloads on data lakes, and almost 9 in 10 expect multiple business departments and functions to benefit from data lake environments. Among organizations with data lakes, our research finds higher levels of organizational satisfaction with the data lake when a data catalog is also in use (61%) than when a data catalog is not in use (47%).
Which is not to say that data catalogs are a panacea. The results of Ventana Research’s Data Governance Benchmark Research show that almost one-half of organizations see being able to manage a catalog on the location of data as a primary concern in managing data effectively. In fact, the proliferation of data catalog functionality in the last decade could be contributing to this challenge. Not only are there multiple standalone data catalog providers, but numerous vendors offer data catalog functionality in data and analytics platforms. Vendor “co-opetition” is critical to ensure that the multiple data catalogs do not become multiple silos of information knowledge. I recommend that organizations take a strategic approach to evaluating data catalog uses and requirements, with a strong focus on support for open standards and interoperability.
Regards,
Matt Aslett
Authors:

Matt Aslett
Director of Research, Analytics and Data
Matt Aslett leads the software research and advisory for Analytics and Data at Ventana Research, now part of ISG, covering software that improves the utilization and value of information. His focus areas of expertise and market coverage include analytics, data intelligence, data operations, data platforms, and streaming and events.








