
Recently, I suggested you need to “mind the gap” between data and analytics. This perspective addresses another gap — the gap in skills between business intelligence (BI) and artificial intelligence/machine learning (AI/ML).
There’s a lot of hype surrounding AI/ML, and for good reason too. Our research shows that the interest in AI/ML is justified. Organizations using AI/ML report it has helped them gain a competitive advantage, improve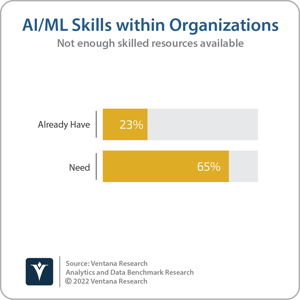 customer experiences and respond faster to opportunities and threats in the market. As a result, it’s not surprising to see that 87% of organizations are using or plan to use AI/ML. The reality, however, is that only one-quarter of organizations are using it today. One of the obstacles to adopting AI/ML is the specialized skill set required to effectively build and deploy models today. Less than one-quarter of organizations (23%) report they have enough AI/ML skilled resources available within their organizations.
customer experiences and respond faster to opportunities and threats in the market. As a result, it’s not surprising to see that 87% of organizations are using or plan to use AI/ML. The reality, however, is that only one-quarter of organizations are using it today. One of the obstacles to adopting AI/ML is the specialized skill set required to effectively build and deploy models today. Less than one-quarter of organizations (23%) report they have enough AI/ML skilled resources available within their organizations.
We’ve seen the rise of augmented intelligence and the use of autoML and other automated analytics based on AI/ML, in part to help address this skills shortage. However, augmented intelligence should not be considered a substitute for robust data science activities. Many situations still require a dedicated, highly skilled data science team for production-quality AI/ML deployments where “good enough” is not good enough.
The complicated nature of building and maintaining AI/ML models requires knowledge of many different algorithms, each with many different parameter settings. Even with hyperparameter optimization included in many AI/ML platforms to speed up the process of finding the optimal parameters to use, there are many steps in the process that require data science expertise. Data preparation remains a critical step, requiring knowledge of how data should be prepared for each algorithm. For instance, does the algorithm require continuous or discreet inputs? If it requires discreet inputs, should the intervals contain equal populations or equal ranges of values? Not only must the data be prepared properly, but it must also be evaluated for bias. If bias exists in the data, it will be reflected in the models it produces. What about overfitting — the generation of a model that corresponds too closely to the data set? Overfit models struggle to perform accurately over unseen data.
For these reasons, we assert that through 2025, AI and machine learning approaches will remain largely independent of business intelligence approaches, requiring three-quarters of organizations to maintain multiple, separate skill sets. All is not lost, however. The outputs of AI/ML models can be valuable to many throughout the organization. They can be shared via standard BI tools and used, for instance, in customer segmentation analyses or customer service recommendations. The expansion and improvement of autoML capabilities will take some burden off the shoulders of data science specialists, both as a result of enabling some simple model development in limited situations, but also by automating some of the routine, repetitive tasks required in AI/ML model development. In addition, once a model is developed, it must be deployed into production and, once in production, needs to be monitored and updated regularly. Fortunately, vendors have developed MLOps tools to address many of these issues which will also help make data science resources more productive.
separate skill sets. All is not lost, however. The outputs of AI/ML models can be valuable to many throughout the organization. They can be shared via standard BI tools and used, for instance, in customer segmentation analyses or customer service recommendations. The expansion and improvement of autoML capabilities will take some burden off the shoulders of data science specialists, both as a result of enabling some simple model development in limited situations, but also by automating some of the routine, repetitive tasks required in AI/ML model development. In addition, once a model is developed, it must be deployed into production and, once in production, needs to be monitored and updated regularly. Fortunately, vendors have developed MLOps tools to address many of these issues which will also help make data science resources more productive.
Organizations need to understand where they may have a gap in skill sets and make realistic plans for the AI/ML deployments. They should also stay on top of technology trends and advances. This segment of the market is changing rapidly. But for the near term, tread lightly on turning over all AI/ML to automated processes. Anticipate the need for a dedicated, highly skilled data science team for production-quality AI/ML deployments where “good enough” is not good enough.
Regards,
David Menninger
Authors:

David Menninger
Executive Director, Technology Research
David Menninger leads technology software research and advisory for Ventana Research, now part of ISG. Building on over three decades of enterprise software leadership experience, he guides the team responsible for a wide range of technology-focused data and analytics topics, including AI for IT and AI-infused software.








