
We at Ventana Research recently published our research agendas for 2018. The world of data and information management continues to evolve, as does our research on the use of these technologies to improve your organization’s operations. Relational databases are no longer the only viable enterprise data store as more organizations adopt a polyglot database infrastructure. And while their exact form may still be changing, as I have recently written, big data technologies are here to stay. Our Data and Analytics in the Cloud Benchmark Research indicates that an increasing number of organizations are opting for cloud-based deployments: A modern data infrastructure includes a hybrid of on-premises and cloud deployments for 44 percent of organizations. Our upcoming research will track how these changes are affecting data- and information-management processes.
We have added a new topic to our research agenda this year: blockchain. While initial implementations of blockchain technology were focused on bitcoin, banking and payment systems, we expect to see it applied to other scenarios as well. My colleague Rob Kugel has written about some of these opportunities in this perspective. We’re expecting that by 2021 one-quarter of all organizations will be using blockchain databases in one or more business processes.
We also are currently researching the adoption of data lakes and their role in organizations’ information architectures. Are they replacing enterprise data warehouses, supplementing them, or are they primarily deployed as independent entities? While some in the industry may consider data lakes to be data swamps, as I have written previously, with proper governance and administration data lakes can be an effective approach to managing and analyzing very large volumes of data. Stay tuned for more information as we analyze the ways organizations are using data lakes.
A month ago we published our Data Preparation Benchmark Research, which examined the intersection of self-service and enterprise data-management requirements. The research reveals some interesting contrasts. While an overwhelming majority of organizations (88%) 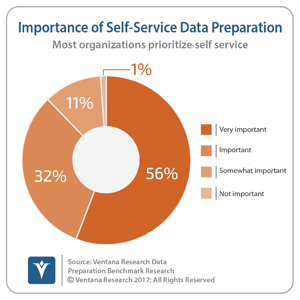 reported that self-service is important, fewer than half (42%) are comfortable allowing users to work directly with data that hasn’t been prepared by IT. We’ll be sharing more insights from this research in the coming months.
reported that self-service is important, fewer than half (42%) are comfortable allowing users to work directly with data that hasn’t been prepared by IT. We’ll be sharing more insights from this research in the coming months.
With the European Union General Data Protection Regulation(GDPR) scheduled to take effect in May, along with growing interest in and concerns about data lakes, we expect data governance will be an important topic for many organizations. In fact, our data preparation research shows that security, governance and risk concerns are the most common reason organizations hesitate to invest in self-service data preparation. We anticipate the run-up to GDPR will be a reprise of the Y2K hysteria, and we expect that nearly every major organization will reevaluate its data-governance processes.
Streaming data is becoming the norm, complicating data governance, information management and analytic processes. With so many connected devices as well as other machine data, organizations now must be capable of processing information as it is generated. Two-thirds of the participants in our IoT Benchmark Research said they consider it essential to process event data within minutes. To explore this area further we’ll be conducting research on the successes organizations achieve and the challenges they face in processing streaming data.
The data and information-management world has become both more powerful, scaling and processing huge volumes of data, and more complicated, requiring a variety of technologies to process all this data. We’ll be studying the issues above and more throughout the year. Please download and review our full Data and Information Management research agenda. I invite you to participate in this research as we conduct it during the year. I look forward to sharing the insights we discover and helping your organization apply those insights to its business needs.
Regards,
David Menninger
SVP & Research Director
Authors:

David Menninger
Executive Director, Technology Research
David Menninger leads technology software research and advisory for Ventana Research, now part of ISG. Building on over three decades of enterprise software leadership experience, he guides the team responsible for a wide range of technology-focused data and analytics topics, including AI for IT and AI-infused software.








