
Recently Hortonworks announced some significant additions to its products at the DataWorks Summit. These additions reflect the fact that the big data market continues to evolve, as I have previously written.
Along with this evolution, the focus is changing from the technical aspects of storing and 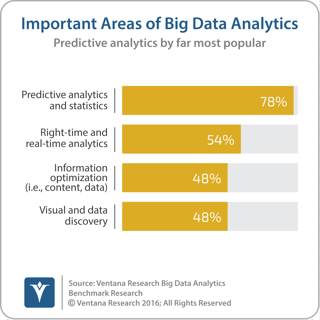 managing very large amounts of data to applying analytics to the data to improve business outcomes. This theme underlies one of Hortonworks’ key announcements: the company has partnered with IBM to combine the Hortonworks Data Platform (HDP) with the machine learning capabilities of IBM’s Data Science Experience and IBM Big SQL. In turn IBM will adopt HDP for its Hadoop distribution.
managing very large amounts of data to applying analytics to the data to improve business outcomes. This theme underlies one of Hortonworks’ key announcements: the company has partnered with IBM to combine the Hortonworks Data Platform (HDP) with the machine learning capabilities of IBM’s Data Science Experience and IBM Big SQL. In turn IBM will adopt HDP for its Hadoop distribution.
The announcement indicates consolidation in the Hadoop segment of the big data market. As recently as three years ago there were six major vendors offering Hadoop distributions. There currently are just three primary Hadoop distributions: from Hortonworks, Cloudera and MapR. More important than consolidation from my perspective, though, is the broadening of the Hortonworks product line. The new machine learning and data science capabilities address the shift in the overall big data market to include the analytics that businesses need to make sense of big data and improve business outcomes. Our Big Data Analytics Benchmark Research identifies predictive analytics and statistics as the most important types of analytics for big data. I’ve written about the importance of predictive analytics (including machine learning) and we are currently furthering our understanding of this topic with a Dynamic Insights research study. I encourage you to participate.
The Hortonworks product line originally consisted primarily of the Apache Hadoop distribution. Hortonworks has focused on delivering a pure open-source version of the big data stack and has found significant acceptance in the market, generating $200 million in revenue in the last four quarters according to its most recent financial statements. In the latter part of 2015 the company added Hortonworks Data Flow (HDF) to the core big data management components of HDP to process streaming data commonly associated with big data implementations.
With these two pieces in place, Hortonworks customers could manage data at rest with HDP and data in motion with HDF, but there was still a missing piece: analytics. Using Hortonworks products, customers could manage the Vs of big data (volume, velocity and variety) but not the As (analytics, awareness, anticipation, and action), which, as I have written, is where the market is headed. The IBM data science and machine learning products fill this gap by providing a set of tools that can be used to perform the types of analytics necessary to derive the maximize value from big data.
With these added pieces, Hortonworks now has a more complete offering to meet more of its customers’ big data needs. The IBM relationship may also prove to benefit the company’s market share; if IBM’s global sales organization puts its muscle behind HDP it could help expand Hortonworks’s sales significantly.
As the big data market continues to evolve, common themes are emerging. Organizations need to deal not only with large volumes of data at rest, but also the streams of data as they are generated. They also need to be able to utilize data science to apply sophisticated analytics to these data sources. With this latest expansion of its product line, customers and prospects can now consider Hortonworks for all three of these needs.
Regards,
David Menninger
SVP & Research Director
Authors:

David Menninger
Executive Director, Technology Research
David Menninger leads technology software research and advisory for Ventana Research, now part of ISG. Building on over three decades of enterprise software leadership experience, he guides the team responsible for a wide range of technology-focused data and analytics topics, including AI for IT and AI-infused software.








