
For decades, data integration was a rigid process. Data was processed in batches once a month, once a week or once a day. Organizations needed to make sure those processes were completed successfully—and reliably—so they had the data necessary to make informed business decisions. The result was battle-tested integrations that could withstand the test of time.
However, as organizations become more agile, so must their information processes. Our Data Preparation Benchmark Research shows that organizations’ most frequent concern with their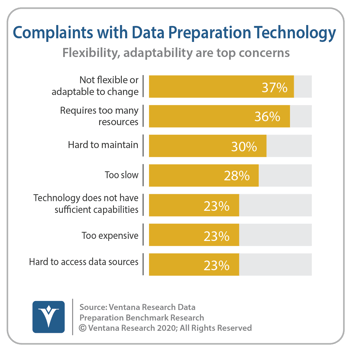 data preparation processes is that they are not flexible or adaptable to change.
data preparation processes is that they are not flexible or adaptable to change.
There are many reasons why organizations need to be more flexible in their data processes. Data sources and targets change. Organizations transition to new data and analytic tools, and migrate some of their systems to the cloud. Lines of business adopt new business processes either to gain a leg up on the competition or to respond to competitive pressures. Markets change. Mergers and acquisitions occur.
DataOps has emerged as an approach to address these issues while still maintaining the appropriate reliability and governance that organizations require. DataOps takes its name from DevOps, which is all about the continuous delivery of software applications in the face of constant changes. As an industry, we are now applying those same concepts to data delivery. Sometimes these continuous delivery approaches are referred to as “day 2” operations; after systems and processes are initially deployed they must be maintained and enhanced.
There is no magical technology that will suddenly enable your organization to adopt a DataOps approach. It is more about embracing a philosophy and processes that recognize the need to manage constant change. The secret ingredient, if there is one, is automation. Not only must data processes be automated—after all, we’ve been doing that for decades—but changes to those processes must be automated as well. Anticipate change and architect your processes to deal with that change smoothly.
Metadata and machine learning can both help. Metadata, or data about the data, can be tracked so that changes in data structures are identified automatically. Some of these changes can be handled easily. For instance, if a table or column in the target system has been eliminated, it no longer needs to be populated. Other changes require more sophisticated analysis to determine the correct result. If a new column has been created in the source system, how have other similar columns (or changes in columns) been treated in the past? Machine learning can be used to make these kinds of determinations and recommend an appropriate course of action.
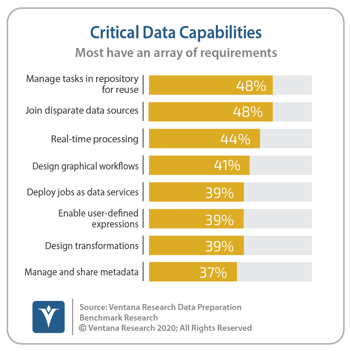
Data integration and preparation processes often involve multiple, interconnected steps. For example, extract data from the marketing systems, then enrich the data with a customer segmentation analysis that may require some transformations to support the specific algorithm being applied. It may be helpful to think of these steps as a pipeline, moving the data through production processes and getting it to the appropriate destination. Each of these steps and the connections between them need to be repeatable and resilient to change. Our research shows the critical data processing capability most often required is the ability to manage data processing tasks in a repository for reuse.
Organizations need to be adaptable and flexible in their business processes to remain competitive in today’s market. Adopting a DataOps approach will help support that flexibility and adaptability. As you move forward, look for tools and technologies that provide a repository-based approach with a rich metadata catalog and machine learning assistance to help identify and remediate changes in the underlying systems. With these capabilities, you will be on your way to supporting DataOps in your organization.
Regards
David Menninger
Authors:

David Menninger
Executive Director, Technology Research
David Menninger leads technology software research and advisory for Ventana Research, now part of ISG. Building on over three decades of enterprise software leadership experience, he guides the team responsible for a wide range of technology-focused data and analytics topics, including AI for IT and AI-infused software.








