
R, the open source programming language for statistics and graphics, has now become established in academic computing and holds significant potential for businesses struggling to fill the analytics skills gap. The software industry has picked up on this potential, and the majority of business intelligence and analytics players have added an R-oriented strategy to their portfolio. In this context, it is relevant to look at some of the problems that R addresses and some of the challenges to its adoption.
As I mentioned, perhaps the most important potential for R is to address the analytic skills gap, which our research shows is a priority for 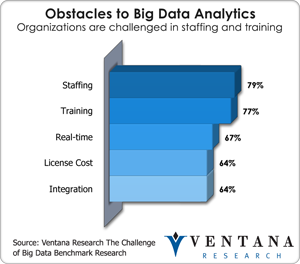 organizations. This is a serious and growing issue as more enterprises try to deal with the huge volumes of data they accumulate now, which continue to increase. Our benchmark research on big data identifies the biggest challenges to implementing big data as staffing (cited by 79% of organizations) and training (77%). Since R is a widely used statistical language used in academia today, current and future graduates may well help fill this gap with what they learned.
organizations. This is a serious and growing issue as more enterprises try to deal with the huge volumes of data they accumulate now, which continue to increase. Our benchmark research on big data identifies the biggest challenges to implementing big data as staffing (cited by 79% of organizations) and training (77%). Since R is a widely used statistical language used in academia today, current and future graduates may well help fill this gap with what they learned.
Another challenge facing companies is the lack of usability of advanced analytic languages and tools. Across our research, usability is rising in importance in just about every category. Analytical programming is not something the information consumer or the knowledge worker can do, as I outlined in a recent analysis on personas in business analytics, but those in the analyst community can readily learn the R language. R’s object-orientation is often put forth as providing an intuitive language that is easier to learn than conventional systems; this starts to explain its massive following, which already numbers in the millions of users.
On another front, R addresses the need for analytics to be part of larger analytic workflows. It is easier to embed into applications than other statistical languages, and unlike embeddable approaches such as Python, R does not require users to pull together a variety of elements to address a particular statistical problem. Fundamentally, R is more mature than Python from an algorithmic point of view, and its terminology is oriented more to the statistical user than the computer programmer.
Perhaps the broadest opportunity for R is to address new use 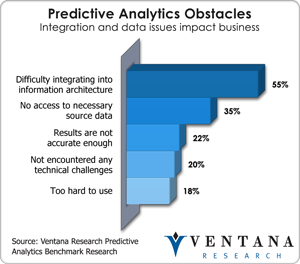 cases and the creation of innovative analytical assets for companies. The fact that it is open source means that each time a new analytical process is developed, it is released and tested almost immediately if submitted through the R project community. Furthermore, R does a nice job of using a diverse set of data which is an important part of doing predictive analytics on big data in today’s highly distributed environments. As I often mention, new information sources are more important than tools and techniques. R does not directly address the largest obstacle found in our predictive analytics research that over half (55%) of organizations found which is difficulty integrating into information architecture that is the ad-hoc or needs to be automated to support the integration of data to support the analytic processes.
cases and the creation of innovative analytical assets for companies. The fact that it is open source means that each time a new analytical process is developed, it is released and tested almost immediately if submitted through the R project community. Furthermore, R does a nice job of using a diverse set of data which is an important part of doing predictive analytics on big data in today’s highly distributed environments. As I often mention, new information sources are more important than tools and techniques. R does not directly address the largest obstacle found in our predictive analytics research that over half (55%) of organizations found which is difficulty integrating into information architecture that is the ad-hoc or needs to be automated to support the integration of data to support the analytic processes.
Last, but not least in terms of opportunities, R addresses the cost pressures that face business users and IT professionals alike. Some might argue that R is free in the way a puppy is free (requiring lots of effort after adoption), but in the context of an organization’s ability to bootstrap an analytic initiative, low startup cost is a critical element. With online courses and a robust community available, analysts can get up to speed quickly and begin to add value with little direct investment from their employers.
Despite all these positive aspects, there are others holding back adoption of R in the enterprise. The downside of being free is the perceived lack of support for enterprises that commit to an open source application. This can be a particularly high barrier in industries with established analytic agendas, such as some areas of banking, consumer products, and Pharmaceutical companies. (Ironically, these industries are some of the biggest innovators with R in other parts of their business.)
And we must note that ease of use for R still seems to stop with an experienced analyst used to a coding paradigm. No graphical user environment such as SPSS Modeler or SAS Data Miner has emerged yet as a standard approach for R but we have seen offerings that are maturing rapidly that I have already covered as stand-alone tools like Revolution Analytics and also embedded within business intelligence tools like Information Builders. Thus the level of user sophistication has to be higher and analytical processes are more difficult to troubleshoot.
Finally, the scalability of R is limited to what is loaded into memory. How large the data sets being analyzed can go is a matter of debate; one LinkedIn group discussion claimed that an R analytic data set can scale to a terabytes in-memory, while my discussions with users suggest that large production implementations are not viable without parallelizing the code in some sort of distributed architecture. Generally speaking, as analytic data sets get into the terabyte range, parallelization is necessary.
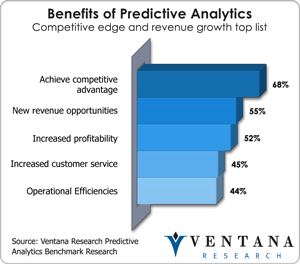 In my next analysis, I will look at some of the industries and companies that are using R to achieve competitive advantage, which according to our benchmark research into predictive analytics is the number one biggest benefit of predictive analytics for more than two-thirds of companies. I will also highlight more updated on how enterprise software vendors’ strategies and where they are incorporating R into their software portfolios.
In my next analysis, I will look at some of the industries and companies that are using R to achieve competitive advantage, which according to our benchmark research into predictive analytics is the number one biggest benefit of predictive analytics for more than two-thirds of companies. I will also highlight more updated on how enterprise software vendors’ strategies and where they are incorporating R into their software portfolios.
Regards,
Tony Cosentino
VP and Research Director
Authors:
Ventana Research
Ventana Research, now part of Information Services Group (ISG), is the most authoritative and respected market research and advisory services firm focused on improving business outcomes through optimal use of people, processes, information and technology. Since our beginning, our goal has been to provide insight and expert guidance on mainstream and disruptive technologies. In short, we want to help you become smarter and find the most relevant technology to accelerate your organization's goals.








