
It has been clear for some time that future enterprise IT architecture will span multiple cloud providers as well as on-premises data centers. As Ventana Research noted in the market perspective on data architectures, the rapid adoption of cloud computing has fragmented where data is accessed or consolidated. We are already seeing that almost one-half (49%) of respondents to Ventana Research’s Analytics and Data Benchmark Research are using cloud computing for analytics and data, of which 42% are currently using more than one cloud provider.
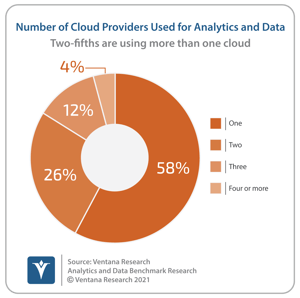 For many organizations, the use of multiple cloud providers may have started accidently, fueled by the individual technology choices made by autonomous departments or regions as well as mergers and acquisitions. Increasingly, multicloud is the strategic choice, however, driven by the desire to take advantage of products and services provided by individual cloud and cloud computing providers as well as avoiding the potential for cloud lock-in. Organizations may not actually want to move workloads between cloud providers in practice, due to complexity and data egress charges, but want to be in a theoretical position to do so if necessary or desired. This is especially true in the financial services sector where multiple regulations now stipulate the need for banks to have documented cloud exit strategies to mitigate the risk of cloud failure.
For many organizations, the use of multiple cloud providers may have started accidently, fueled by the individual technology choices made by autonomous departments or regions as well as mergers and acquisitions. Increasingly, multicloud is the strategic choice, however, driven by the desire to take advantage of products and services provided by individual cloud and cloud computing providers as well as avoiding the potential for cloud lock-in. Organizations may not actually want to move workloads between cloud providers in practice, due to complexity and data egress charges, but want to be in a theoretical position to do so if necessary or desired. This is especially true in the financial services sector where multiple regulations now stipulate the need for banks to have documented cloud exit strategies to mitigate the risk of cloud failure.
Many organization’s computing workloads have already moved from on-premises data centers to the cloud, and we expect that trend to continue. However, there are good reasons for keeping some analytics and data workloads on premises. Security is a primary concern, cited by 57% of organizations not planning to use the cloud for analytics and data in Ventana Research’s Analytics and Data Benchmark Research, followed by a lack of skills or resources (39%), and regulatory reasons (26%). Clearly, the IT architecture of the future will not only be multicloud but a hybrid of cloud and on-premises compute resources. As compute and storage is distributed across a hybrid and multicloud architecture, so, too, is the data it stores and relies upon. Hence our assertion that by 2025, more than three-quarters of organizations will have data spread across multiple cloud providers and on-premises data centers, requiring investment in data management products that span multiple locations.
 As such, there is a growing requirement for cloud-agnostic data platforms, both operational and analytic, that can support data processing across hybrid IT and multi-cloud environments. For analytic workloads, this means data platforms that can access and query data in multiple locations. For operational workloads it means data platforms that can span multiple regions and data center resource providers. Most data platform vendors today are talking up their hybrid and multicloud credentials. As always, they are not necessarily using the same terminology, and the fine print is worth close consideration. For example, offering a data platform that can be deployed both on-premises and on a variety of clouds is not the same thing as offering a data platform that can span an on-premises data center and/or multiple clouds.
As such, there is a growing requirement for cloud-agnostic data platforms, both operational and analytic, that can support data processing across hybrid IT and multi-cloud environments. For analytic workloads, this means data platforms that can access and query data in multiple locations. For operational workloads it means data platforms that can span multiple regions and data center resource providers. Most data platform vendors today are talking up their hybrid and multicloud credentials. As always, they are not necessarily using the same terminology, and the fine print is worth close consideration. For example, offering a data platform that can be deployed both on-premises and on a variety of clouds is not the same thing as offering a data platform that can span an on-premises data center and/or multiple clouds.
Among the vendors targeting the latter in the relational operational segment, there is a new group of data platform providers promising global scalability. Once referred to as NewSQL database providers, many of these organizations have adopted the term distributed SQL to better highlight the fact that products and services were designed to combine the benefits of the relational database model and native support for distributed cloud architecture, including resilience that spans multiple data centers and/or cloud regions. For non-relational workloads there is a collection of NoSQL providers that are also targeting multiregional and multicloud use-cases. Regardless of the data model, there are similar use-cases and requirements that are driving interest in hybrid and multi-cloud data platforms.
One of the primary reasons for investing in data platforms that span both on-premises and cloud resources is business continuity. The cloud provides a more cost-efficient option for insuring against on-premises data center failure than building a secondary data center that may be idle for much of the time. Data platforms capable of failing over from an on-premises data center to the public cloud are therefore nothing new, but distributed SQL and NoSQL data platforms that automatically replicate data across locations and rebalance in the event of failure (and recovery) can claim to have been architected from scratch for high-availability and disaster recovery, providing active-active architecture that avoids the risks of data loss and delays that come with active-passive deployments. Clearly business continuity is also a primary driver for multiregional cloud data platforms, for the same reasons cited above in relation to active-active replication of data to avoid the risks associated with regional cloud failures.
This active-active replication is also important in supporting cloud bursting in response to additional capacity requirements, as is the ability to automatically scale down cloud resources when they are no longer required. This ability to add cloud resources as required is not just a matter of scalability, however. Some workloads are by nature ephemeral and will lend themselves to being deployed on virtualized resources that can be quickly provisioned and deprovisioned, while others have specific performance requirements that are better suited to long-lived resources. Workload isolation also enables the separation of nodes dedicated to operational and analytics workloads on the same data, and is also potentially significant in terms of regulatory considerations that may compel organizations to retain workloads in a specific geographic location, either on-premises, or in a specific cloud region. Data sovereignty remains an important consideration that can drive adoption of multiregional data platforms, with the potential to provide an abstraction layer to data that might need to reside in a specific location but could still be used to support operational and analytic workloads that span multiple regions. On the opposite side of the coin, latency is a consideration for multiregional data platforms that can scale by replicating or distributing data that is not subject to regulatory limitations, supporting local performance requirements by minimizing network delays between the data platform and users across multiple regions.
For those organizations that are extremely risk-averse in relation to business continuity, the ability for a data platform to span multiple cloud providers can add an additional layer of confidence in relation to disaster recovery and high-availability planning. While there are theoretical risks associated with being reliant on a single cloud provider, in most cases the chances of requiring a data platform to failover not just across regions but across cloud providers are very low. In addition to latency and sovereignty, geographic availability (or the lack of it) is likely to be a driver for a multicloud approach. Although the major cloud providers all boast of coverage that spans the globe, not all cloud providers are available in every region. If an organization has a requirement to provide availability in a specific country (particularly in underserved areas such as South America, Africa and parts of Asia), there may be no choice but to utilize multiple cloud providers — either by using multiple hyperscalers or combining a single hyperscale provider with a regional specialist provider. For organizations that have no option but to use multiple cloud providers, selecting a data platform provider that spans multiple clouds and multiple regions can provide a level of consistency in terms of skillset and application certification, in addition to meeting business continuity, latency and sovereignty needs.
A single data platform that can span multiple regions and multiple clouds as well as on-premises deployment could potentially tick all the boxes in terms of business continuity, latency and sovereignty as well as consistency. “Potentially” is a key word here as data platforms that can deliver on that promise remain a work in progress. Delivering global transactional integrity across multiple regions and data centers/cloud providers is one of the most complex data challenges there is. Nevertheless, this will be an increasing focus for organizations, and Ventana Research’s data platforms research going forward. I recommend that plans to span multiple data centers and cloud providers should at the very least be on the list of considerations as organizations reconsider options for data platform providers to support future data and analytics requirements.
Regards,
Matt Aslett
Authors:

Matt Aslett
Director of Research, Analytics and Data
Matt Aslett leads the software research and advisory for Analytics and Data at Ventana Research, now part of ISG, covering software that improves the utilization and value of information. His focus areas of expertise and market coverage include analytics, data intelligence, data operations, data platforms, and streaming and events.








