
One of the most significant considerations when choosing an analytic data platform is performance. As organizations compete to benefit most from being data-driven, the lower the time to insight the better. As data practitioners have learnt over time, however, lowering time to insight is about more than just high-performance queries. There are opportunities to improve time to insight throughout the analytics life cycle, which starts with data ingestion and integration, includes data preparation and data management, as well as data storage and processing, and ends with data visualization and analysis. Vendors focused on delivering the highest levels of analytic performance, such as SQream, understand that lowering time to insight relies on accelerating every aspect of that life cycle.
SQream Technologies was founded in 2010 to develop a relational analytic data platform designed to exploit graphical processing units (GPUs) to deliver high-performance SQL-based analytics on large-scale datasets. 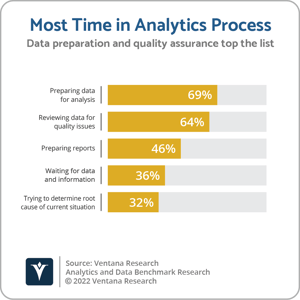 The use of GPUs to accelerate memory-intensive computations, such as the rendering of two- and three-dimensional graphics, was already established in use cases such as video gaming and medical imaging. SQream was one of a handful of vendors that emerged at a similar time with a view to establishing the use of GPUs to accelerate the analysis of large data volumes in industries such as finance, telecommunications, genomics and cybersecurity. The company’s growth has been aided by the increasingly widespread availability of GPU-based server infrastructure, both on-premises and from the major cloud providers, as well as growing demand for machine learning (ML) and deep learning on large-scale datasets, the performance requirements for which can exceed the limitations of central processing unit (CPU)-based systems. SQream has also benefitted by expanding its core SQream DB database into a Data Acceleration Platform, complementing its high-performance data processing capabilities with functionality to accelerate data ingestion, reduce infrastructure footprint requirements through data compression, and provide support for common ML and predictive analytics environments. In late 2021, SQream added data integration and data management capabilities to its portfolio with the acquisition of Panoply and its no-code extract, load and transform (ELT) and data warehouse management functionality. Panoply’s software-as-a-service (SaaS) availability and no-code approach has helped SQream extend its customer base into small enterprises and departments of larger organizations. It is also an important component in SQream’s focus on improving overall time to insight. More than two-thirds of participants (69%) in our Analytics and Data Benchmark Research cited preparing data for analysis as being the most time-consuming aspect of analytics initiatives. SQream is now focused on an expanded set of industries, including healthcare, manufacturing, retail, ad tech, as well as finance, telecoms, pharmaceutical and cybersecurity. Named SQream customers include AIS, Cellcom, LG, Orange, PubMatic, and Vodafone, while target use cases include financial reporting, customer churn analysis, personalization, anomaly detection, data retention, and network quality of service. SQream’s growth has been fueled by venture capital funding, the most recently announced being a $39.4 million Series B round led by Mangrove Capital Partners and Schusterman Family Investments.
The use of GPUs to accelerate memory-intensive computations, such as the rendering of two- and three-dimensional graphics, was already established in use cases such as video gaming and medical imaging. SQream was one of a handful of vendors that emerged at a similar time with a view to establishing the use of GPUs to accelerate the analysis of large data volumes in industries such as finance, telecommunications, genomics and cybersecurity. The company’s growth has been aided by the increasingly widespread availability of GPU-based server infrastructure, both on-premises and from the major cloud providers, as well as growing demand for machine learning (ML) and deep learning on large-scale datasets, the performance requirements for which can exceed the limitations of central processing unit (CPU)-based systems. SQream has also benefitted by expanding its core SQream DB database into a Data Acceleration Platform, complementing its high-performance data processing capabilities with functionality to accelerate data ingestion, reduce infrastructure footprint requirements through data compression, and provide support for common ML and predictive analytics environments. In late 2021, SQream added data integration and data management capabilities to its portfolio with the acquisition of Panoply and its no-code extract, load and transform (ELT) and data warehouse management functionality. Panoply’s software-as-a-service (SaaS) availability and no-code approach has helped SQream extend its customer base into small enterprises and departments of larger organizations. It is also an important component in SQream’s focus on improving overall time to insight. More than two-thirds of participants (69%) in our Analytics and Data Benchmark Research cited preparing data for analysis as being the most time-consuming aspect of analytics initiatives. SQream is now focused on an expanded set of industries, including healthcare, manufacturing, retail, ad tech, as well as finance, telecoms, pharmaceutical and cybersecurity. Named SQream customers include AIS, Cellcom, LG, Orange, PubMatic, and Vodafone, while target use cases include financial reporting, customer churn analysis, personalization, anomaly detection, data retention, and network quality of service. SQream’s growth has been fueled by venture capital funding, the most recently announced being a $39.4 million Series B round led by Mangrove Capital Partners and Schusterman Family Investments.
The acceleration of data processing using GPUs is at the heart of SQream’s value proposition, but the company’s SQream DB database does not run exclusively on GPUs. The company describes its offering as a hybrid analytics platform that supports data processing based on a combination of multi-core CPUs, GPUs, RAM and storage resources. While GPUs perform best when parallelizing multiple, repetitive operations on large amounts of data, CPUs are a better fit for text processing and operations for which there may be an excessive overhead involved in copying data from the CPU to the GPU. These considerations (and others) are assessed by SQream DB’s Statement Compiler based on the nature of the operation being performed. SQream DB also features a columnar engine that provides access to selective columns, reducing disk scan and memory I/O overheads. For compute-intensive operations suited to GPUs, SQream DB can enable improved query performance for large (terabyte and petabyte) workloads. In addition to raw query performance, SQream also delivers accelerated data ingestion (claiming up to 3TB per hour, per GPU), as well as automated data compression assisted by artificial intelligence (AI) and efficient storage hardware usage via spooling, caching and parallel chunk processing. SQream DB provides integration with standard data integration tools, as well as business intelligence (BI) and visualization applications, and common ML frameworks such as Apache Spark MLlib, R, and TensorFlow. The company’s acquisition of Panoply served to address one of the most time-consuming aspects of any analytics initiative by providing a low-code cloud platform for ELT, as well as data warehouse management. As I have previously noted, rather than a separate transformation stage prior to loading, ELT pipelines make use of pushdown optimization, leveraging the data processing functionality and processing power of the target data platform to transform the data. I assert that by 2025, more than three-quarters of organizations’ information architectures will support ELT patterns to accelerate data processing and maximize the value of large volumes of data. Additionally, while data can be ingested into SQream DB from cloud storage and the Hadoop Distributed File System, SQream DB also provides support for foreign tables to run queries on external data — including ORC, Parquet and text files — without inserting the data in SQream DB. The greatest argument in favor of this combination of capabilities is improving time to insight. However, SQream also points to environmental efficiency and sustainability concerns in relation to analytic and ML workloads and recently highlighted data from the Green Algorithms project that illustrated the potential for carbon footprint reductions.
its offering as a hybrid analytics platform that supports data processing based on a combination of multi-core CPUs, GPUs, RAM and storage resources. While GPUs perform best when parallelizing multiple, repetitive operations on large amounts of data, CPUs are a better fit for text processing and operations for which there may be an excessive overhead involved in copying data from the CPU to the GPU. These considerations (and others) are assessed by SQream DB’s Statement Compiler based on the nature of the operation being performed. SQream DB also features a columnar engine that provides access to selective columns, reducing disk scan and memory I/O overheads. For compute-intensive operations suited to GPUs, SQream DB can enable improved query performance for large (terabyte and petabyte) workloads. In addition to raw query performance, SQream also delivers accelerated data ingestion (claiming up to 3TB per hour, per GPU), as well as automated data compression assisted by artificial intelligence (AI) and efficient storage hardware usage via spooling, caching and parallel chunk processing. SQream DB provides integration with standard data integration tools, as well as business intelligence (BI) and visualization applications, and common ML frameworks such as Apache Spark MLlib, R, and TensorFlow. The company’s acquisition of Panoply served to address one of the most time-consuming aspects of any analytics initiative by providing a low-code cloud platform for ELT, as well as data warehouse management. As I have previously noted, rather than a separate transformation stage prior to loading, ELT pipelines make use of pushdown optimization, leveraging the data processing functionality and processing power of the target data platform to transform the data. I assert that by 2025, more than three-quarters of organizations’ information architectures will support ELT patterns to accelerate data processing and maximize the value of large volumes of data. Additionally, while data can be ingested into SQream DB from cloud storage and the Hadoop Distributed File System, SQream DB also provides support for foreign tables to run queries on external data — including ORC, Parquet and text files — without inserting the data in SQream DB. The greatest argument in favor of this combination of capabilities is improving time to insight. However, SQream also points to environmental efficiency and sustainability concerns in relation to analytic and ML workloads and recently highlighted data from the Green Algorithms project that illustrated the potential for carbon footprint reductions.
Along with other providers of databases designed to utilize GPUs, SQream faces a challenge to educate the market and address conceptions that GPU databases are suitable only for a niche selection of workloads. While it is true that there are workload characteristics that are better suited to GPUs, SQream DB is by no means limited to GPU-based processing. There are opportunities for the company to assist customers in understanding the nature of their workloads and the most efficient combination of CPUs, GPUs, RAM and storage with which to address them. Additionally, thanks to its data ingestion and ELT capabilities, SQream has multiple options for reducing time to insight. I recommend that organizations with large-scale analytics requirements should consider SQream in their evaluations of potential analytic data platform vendors.
Regards,
Matt Aslett
Authors:

Matt Aslett
Director of Research, Analytics and Data
Matt Aslett leads the software research and advisory for Analytics and Data at Ventana Research, now part of ISG, covering software that improves the utilization and value of information. His focus areas of expertise and market coverage include analytics, data intelligence, data operations, data platforms, and streaming and events.








