The data and analytics sector rightly places great importance on data quality: Almost two-thirds (64%) of participants in Ventana Research’s Analytics and Data Benchmark Research cite reviewing data for quality and consistency issues as the most time-consuming task in analyzing data. Data and analytics vendors would not recommend that customers use tools known to have data quality problems. It is somewhat surprising, therefore, that data and analytics vendors are rushing to encourage customers to incorporate large language models into analytics processes, despite LLMs sometimes generating content that is inaccurate and untrustworthy.
LLMs are a form of generative AI. As my colleague Dave Menninger recently explained, generative AI creates content such as text, digital images, audio, video or even computer programs and models with artificial intelligence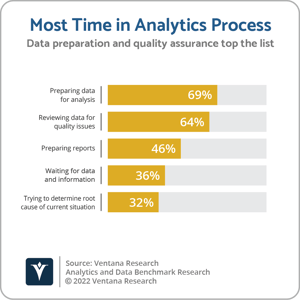 and machine learning. These applications are primarily novelties today, but vendors are incorporating them into data and analytics products and customer experience applications at a rapid rate.
and machine learning. These applications are primarily novelties today, but vendors are incorporating them into data and analytics products and customer experience applications at a rapid rate.
The enthusiasm for generative AI is currently focused primarily on LLMs such as language models for dialogue applications, generative pre-trained transformers and applications such as ChatGPT and Bard. At Ventana Research, we view LLMs as an extraordinary scientific achievement with enormous potential to increase productivity by improving natural language processing. The content generated by LLMs can be remarkably coherent, to the extent that GPT-4 produces results that can pass the multiple-choice and written portions of the Uniform Bar Exam. LLMs are not without fault, however, and there are no guarantees about the factual accuracy of the content generated. While there is huge excitement about LLMs, we are still learning about their practical benefits and limitations. As a result, vendors and users should proceed with caution.
LLMs produce content by automatically generating sentences in response to a prompt based on a (slightly randomized) selection of words from a probabilistically ranked list. The conversational nature of LLMs like ChatGPT makes them intuitively easy to use. As such, they can be seen as an ideal interface for non-expert users. However, LLMs generate content that is grammatically valid rather than factually accurate. As a result, the content generated by LLMs is occasionally incoherent and incorrect. It can include factual inaccuracies, such as fictitious data and source references. Additionally, LLMs trained on existing information sources will reflect the biases inherent in the source information. Identifying inaccuracies and biases in content generated by LLMs may not be easy for people without domain-specific knowledge, making LLMs potentially inappropriate for many workers.
Users and vendors should also be wary of creating a misplaced level of trust in the quality and validity of the output of LLMs by crediting them with a level of conscious intelligence they do not possess. Interface design choices and anthropomorphic terminology can create an impression of sentience that is unjustified. The term adopted to describe the tendency of LLMs to generate text that is plausible but incorrect — hallucination — is a prime example. LLMs do not hallucinate, although they can (and do) generate content that is plausible but incorrect. Similarly, despite interfaces that are designed to mimic human consciousness, LLMs are not conscious. Likewise, while LLMs generate text that creates the appearance of self-awareness, they are (currently) not self-aware. In combination with the human tendency towards pareidolia (perceiving pattern or meaning where there is none), anthropomorphic terminology and interfaces could create a misplaced level of trust in LLMs and the quality and accuracy of the output they generate.
There is a risk that this could result in an organization making a costly business decision based on erroneous information. Legal disputes will likely follow. Even if the fault ultimately lies with the decision maker, vendors that provide access to LLMs without due warning about their potential to produce inaccurate results could find themselves in the spotlight. As my colleague Dave Menninger recently noted, OpenAI, Google, Microsoft and others are clear with users about the accuracy limitations of ChatGPT. Meanwhile Casetext, the company that tested GPT-4 against the Uniform Bar Exam, has warned that ChatGPT alone is not enough and has combined the underlying LLM functionality with tailoring, training and testing based on its legal and data security expertise to produce an application that is suitable for use by legal professionals. Many vendors are cautious about encouraging enterprises to think carefully about using LLMs, advising them to think about privately combining models with organizational data and expertise rather than integrating with and uploading data to publicly available applications.
provide access to LLMs without due warning about their potential to produce inaccurate results could find themselves in the spotlight. As my colleague Dave Menninger recently noted, OpenAI, Google, Microsoft and others are clear with users about the accuracy limitations of ChatGPT. Meanwhile Casetext, the company that tested GPT-4 against the Uniform Bar Exam, has warned that ChatGPT alone is not enough and has combined the underlying LLM functionality with tailoring, training and testing based on its legal and data security expertise to produce an application that is suitable for use by legal professionals. Many vendors are cautious about encouraging enterprises to think carefully about using LLMs, advising them to think about privately combining models with organizational data and expertise rather than integrating with and uploading data to publicly available applications.
We expect the adoption of generative AI to grow rapidly, asserting that through 2025, one-quarter of organizations will deploy generative AI embedded in one or more software application. Much of this adoption will come from the incorporation of LLMs into data and analytics tools. While vendors and users of data and analytics products are understandably excited about taking advantage of LLMs, both should approach with caution. I recommend that organizations carefully research the implications of making decisions based on information for which there are no guarantees of accuracy, while vendors integrating products with LLMs should balance enthusiasm with advice to customers about checking the quality and validity of responses before making decisions based on content generated by LLMs.
Regards,
Matt Aslett

Matt Aslett
Director of Research, Analytics and Data
Matt Aslett leads the software research and advisory for Analytics and Data at ISG Software Research, covering software that improves the utilization and value of information. His focus areas of expertise and market coverage include analytics, data intelligence, data operations, data platforms, and streaming and events.








