
I have written recently about the similarities and differences between data mesh and data fabric. The two are potentially complementary. Data mesh is an organizational and cultural approach to data ownership, access and governance. Data fabric is a technical approach to automating data management and data governance in a distributed architecture. There are various definitions of data fabric, but key elements include a data catalog for metadata-driven data governance and self-service, agile data integration.
There are several startup vendors targeting the opportunities for data fabric. However, given the breadth of capabilities addressed, companies with a wide portfolio of functionality and a rich history in the data management sector, like IBM, are well-positioned to serve the requirements that drive organizations to seek out a data fabric approach.
IBM has long been a serious contender in the data sector, thanks to a variety of products including:
- Operational data platforms, including IBM Db2 and IBM Cloudant.
- Analytic data platforms, such as IBM Db2 Warehouse.
- Data integration, using IBM DataStage.
- Data governance, supported by IBM Watson Knowledge Catalog.
- Artificial intelligence and machine learning via IBM Watson.
- And business intelligence through IBM Cognos Analytics.
The breadth and depth of IBM’s product portfolio is such that it could be said to have at least one product offering for any given use case. This has helped the company build a large, diverse and growing customer base. However, a vendor portfolio with a large range of offerings can lead to confusion as well as potentially complex and costly integration initiatives involving multiple, stand-alone products and services. In 2019, IBM introduced its Cloud Pak products to address this potential concern, bringing together software covering a variety of requirements in a family of unified, containerized platforms designed to accelerate modernization in public and private cloud environments.
There are currently six IBM Cloud Pak offerings focused on security, network automation, application and data integration, IT operations, business automation and data and analytics. The last of those — IBM Cloud Pak for Data — is IBM’s offering to address data fabric. It provides a single environment for facilitating data management and processing across multiple data and cloud environments.
IBM Cloud Pak for Data combines functionality for data compute, management and governance with automation and AI to support self-service analytics and data science. Although the use cases for this combination of functionality are many and varied, typical entry points driving customer interest include data governance and compliance, customer 360, data integration, data observability and MLOps for trustworthy AI initiatives.
While Cloud Pak for Data can be used for a variety of use cases, a key focus is to increase value by enabling the use of AI/ML to help customers move beyond traditional dashboarding and analytics. Adoption 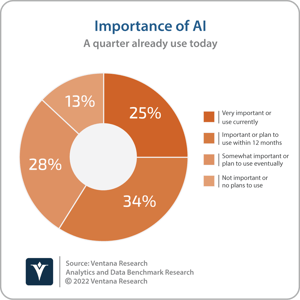 of AI/ML is still in the relatively early stages. One-quarter (25%) of participants in Ventana Research’s Analytics and Data Benchmark Research currently use AI/ML, although more than one-third (34%) plan to do so in the next 12 months, and a further 28% plan to do so eventually. IBM positions data fabric as an ideal approach to enabling greater use of AI/ML by providing a framework for supporting the full model development and deployment life cycle via an integrated data catalog for data governance as well as data pipeline monitoring and management through model development to consumption.
of AI/ML is still in the relatively early stages. One-quarter (25%) of participants in Ventana Research’s Analytics and Data Benchmark Research currently use AI/ML, although more than one-third (34%) plan to do so in the next 12 months, and a further 28% plan to do so eventually. IBM positions data fabric as an ideal approach to enabling greater use of AI/ML by providing a framework for supporting the full model development and deployment life cycle via an integrated data catalog for data governance as well as data pipeline monitoring and management through model development to consumption.
IBM Cloud Pak for Data is built on IBM’s Red Hat OpenShift container platform, and can be deployed on any private or public cloud environment. The same functionality is also available as Cloud Pak for Data System — a hyperconverged environment combining compute, storage networking and software — as well as Cloud Pak for Data as a Service, a managed service on IBM public cloud integrated with on-premises data via IBM Cloud Satellite. Cloud Pak for Data is designed to facilitate the management of data across distributed data stores and clouds, with unified data security and privacy, enabling business intelligence as well as AI/ML use cases. It is designed to reduce complexity and facilitate adoption through the combination of data management, data processing and analytics functionality.
This approach of combining data management, data processing and analytics is not unique to IBM. I assert that through 2024, analytic data platform vendors will continue to accelerate the delivery of  actionable insight by incorporating native data integration, data management, analytics and ML with core data persistence and processing functionality.
actionable insight by incorporating native data integration, data management, analytics and ML with core data persistence and processing functionality.
What differentiates IBM is the breadth of functionality on offer and the level of freedom customers have to pick and choose functionality. IBM’s Cloud Paks are modular platforms that provide a wide choice of optional services from IBM and its partners. In the case of IBM Cloud Pak for Data, those options include data storage and processing, developer tools, data governance, visualization, analytics and AI. As such, no two IBM Cloud Pak for Data deployments are likely to be exactly alike. However, key components of Cloud Pak for Data include IBM Watson Knowledge Catalog for data discovery, cataloging and governance; IBM DataStage for data integration; IBM InfoSphere Data Replication; IBM Data Virtualization; IBM Db2 database and Db2 Warehouse; the IBM Watson Query distributed query engine; IBM Watson Studio for AI/ML model development and operations; and IBM OpenPages with Watson for governance, risk and compliance.
Thanks to multiple, often vendor-centric, definitions, I believe there is still confusion in the industry about the precise nature of data fabric. It is not clear at this stage whether the term is sticky and definitive enough to become a true product category. Nonetheless, it is true that many organizations are looking to advance approaches to data integration and data management, particularly to address the complexities of distributed data storage and processing and support business intelligence and data science initiatives. As such, I recommend that organizations considering options to update data management explore IBM Cloud Pak for Data as a foundation, given the flexibility it provides to support multiple use cases with a choice of services from both IBM and its partners.
Regards,
Matt Aslett
Authors:

Matt Aslett
Director of Research, Analytics and Data
Matt Aslett leads the software research and advisory for Analytics and Data at Ventana Research, now part of ISG, covering software that improves the utilization and value of information. His focus areas of expertise and market coverage include analytics, data intelligence, data operations, data platforms, and streaming and events.








