
I recently described how the data platforms landscape will remain divided between analytic and operational workloads for the foreseeable future. Analytic data platforms are designed to store, manage, process and analyze data, enabling organizations to maximize data to operate with greater efficiency, while operational data platforms are designed to store, manage and process data to support worker-, customer- and partner-facing operational applications. At the same time, however, we see increased demand for intelligent applications infused with the results of analytic processes, such as personalization and artificial intelligence-driven recommendations. The need for real-time interactivity means that these applications cannot be served by traditional processes that rely on the batch extraction, transformation and loading of data from operational data platforms into analytic data platforms for analysis. Instead, they rely on analysis of data in the operational data platform itself via hybrid data processing capabilities to accelerate worker decision-making or improve customer experience.
 The emergence of these intelligent applications does not eradicate the need for separate analysis of data in an analytic data platform (such as a data warehouse or data lake). It does, however, significantly impact the requirements for operational data platforms. We assert that through 2026, operational data platform providers will continue to invest in hybrid operational and analytic processing capabilities to support growing demand for intelligent operational applications infused with personalization and AI-driven recommendations. My colleagues at Ventana Research have provided numerous examples in recent months of operational application use-cases that are being improved via the infusion of intelligence. Examples included providing service agents with contextually relevant information to improve customer service and support; using AI-assisted sales forecasts to help validate bottom-up sales forecast projections; powering chatbots and intelligent virtual assistants to improve contact center efficiency; and delivering the output of predictive models to enhance sales effectiveness.
The emergence of these intelligent applications does not eradicate the need for separate analysis of data in an analytic data platform (such as a data warehouse or data lake). It does, however, significantly impact the requirements for operational data platforms. We assert that through 2026, operational data platform providers will continue to invest in hybrid operational and analytic processing capabilities to support growing demand for intelligent operational applications infused with personalization and AI-driven recommendations. My colleagues at Ventana Research have provided numerous examples in recent months of operational application use-cases that are being improved via the infusion of intelligence. Examples included providing service agents with contextually relevant information to improve customer service and support; using AI-assisted sales forecasts to help validate bottom-up sales forecast projections; powering chatbots and intelligent virtual assistants to improve contact center efficiency; and delivering the output of predictive models to enhance sales effectiveness.
Other examples of applications that benefit from hybrid data processing include fraud detection/prevention in credit approval processes; predictive maintenance and anomaly detection in manufacturing/IoT; and supply chain planning and forecasting in retail/logistics. In some cases, these operational applications deliver the output of an analytic process that began in an external analytic data platform. For example, a recommendation model might be trained in an external data warehouse using historical data, but to deliver recommendations in real time the model needs to run on the data platform that processes the data as it is generated by the operational application. In other cases, the operational application requires standalone analytic processing of operational data, for example to deliver live visualization of data to aid a decision-making process in real time.
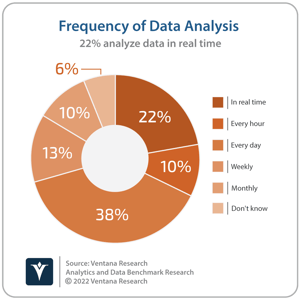
As I previously noted, there have always been general-purpose databases that could be used for both analytic and operational workloads. If both analytic and operational workloads run on the same database concurrently, however, the key challenge is to ensure that the analytic processing does not impact the performance of the operational processing. The need to protect the performance of the operational workload is precisely why traditional architectures have involved the extraction, transformation and loading of data from the operational data platform into an external data platform, enabling the operational and analytic workloads to run concurrently without adversely impacting each other. Over time, dedicated analytic data platforms have also evolved differentiated architectural approaches designed to improve query performance. A prime example would be the use of column-based tables to support high-performance, complex queries, compared to row-based tables, which support the high-performance writes required for transactional operational applications. While this functionality accelerates data analysis, there is inherent latency caused by the extraction, transformation and loading of data from operational applications into the analytic data platforms. This delay is increasingly problematic given the increasing demand for real-time data analysis. Almost one-quarter (22%) of participants to Ventana Research’s Analytics and Data Benchmark Research analyze the data they collect in real time.
 The rise of hybrid data processing is driven by the desire to reduce the complexity and latency caused by that extraction, transformation and loading stage as well as reducing the need to configure, manage and maintain multiple data platforms. There are several approaches to delivering on this goal, which involve collocating operational and analytic data processing functionality in the same data platform. This could be achieved through the concurrent use of both row and column stores in a single data platform node. In a multi-node distributed architecture, it can be achieved by replicating data across the cluster and dedicating individual node clusters for operational and analytics workloads respectively. Either way, there is also the need for additional functionality, such as workload isolation, workload management and query optimization to ensure that the hybrid data processing is being conducted efficiently and that the benefits of removing the separate analytic data platform are not undone by the complexity of replicating data across multiple stores or nodes. Additionally, while the use of hybrid data processing supports the delivery of intelligent operational applications, it does not eradicate the need for a separate data warehouse or data lake to support strategic business intelligence and data science workloads.
The rise of hybrid data processing is driven by the desire to reduce the complexity and latency caused by that extraction, transformation and loading stage as well as reducing the need to configure, manage and maintain multiple data platforms. There are several approaches to delivering on this goal, which involve collocating operational and analytic data processing functionality in the same data platform. This could be achieved through the concurrent use of both row and column stores in a single data platform node. In a multi-node distributed architecture, it can be achieved by replicating data across the cluster and dedicating individual node clusters for operational and analytics workloads respectively. Either way, there is also the need for additional functionality, such as workload isolation, workload management and query optimization to ensure that the hybrid data processing is being conducted efficiently and that the benefits of removing the separate analytic data platform are not undone by the complexity of replicating data across multiple stores or nodes. Additionally, while the use of hybrid data processing supports the delivery of intelligent operational applications, it does not eradicate the need for a separate data warehouse or data lake to support strategic business intelligence and data science workloads.
Organizations need to think carefully about the best architectural approaches to deliver the functionality required for any given use-case. We continue to believe that, for most use cases, there is a clear, functional requirement for either analytic or operational data platforms. However, it is also true to say that an increasing proportion of those operational data platform workloads involve supporting intelligent applications infused with analytic processing. I recommend that organizations evaluating potential database providers for new operational applications should consider data platforms capable of delivering hybrid data processing as a potential alternative —or complement — to more traditional approaches that involve two separate data platforms.
Regards,
Matt Aslett
Authors:

Matt Aslett
Director of Research, Analytics and Data
Matt Aslett leads the software research and advisory for Analytics and Data at Ventana Research, now part of ISG, covering software that improves the utilization and value of information. His focus areas of expertise and market coverage include analytics, data intelligence, data operations, data platforms, and streaming and events.








