
I previously explained how the data lakehouse is one of two primary approaches being adopted to deliver what I have called a hydroanalytic data platform. Hydroanalytics involves the combination of data warehouse and data lake functionality to enable and accelerate analysis of data in cloud storage services. The term data lakehouse has been rapidly adopted by several vendors in recent years to describe an environment in which data warehousing functionality is integrated into the data lake environment, rather than coexisting alongside. One of the vendors that has embraced the data lakehouse concept and terminology is Dremio, which recently launched the general availability of its Dremio Cloud data lakehouse platform.
Dremio was founded in 2015 to build a business around the Apache Arrow in-memory columnar data format, which was developed to enable high-performance analysis of large volumes of data. The company built a SQL query engine, now known as Dremio Sonar, to accelerate the use of standard business intelligence (BI) and visualization software to perform ad hoc analytics and dashboard-based analysis of data in data lake environments. Dremio also recently announced the preview release of Dremio Arctic, a metadata and data management service for the Apache Iceberg table format.
The combination of Dremio Sonar and Dremio Arctic is positioned as a data lakehouse platform. It is available via the Dremio Cloud managed-service offering or as self-managed software to run on a customer’s preferred cloud or data center environment. The core functionality of Dremio Cloud is free to use, with the company only charging for the Enterprise Edition, which includes security and data-masking capabilities, as well as commercial support.
Dremio customers include the likes of Airbus, Bose, Goldman Sachs, Hertz, HSBC, Prudential, Rakuten, and Samsung. The company has also attracted the interest of investors and has raised more than $400 million in funding from the likes of Adams Street Partners, Cisco Investments. Insight Partners, Lightspeed Venture Partners, Norwest Venture Partners, and Sapphire Ventures, with the latest $160 million Series E round valuing the company at $2 billion.
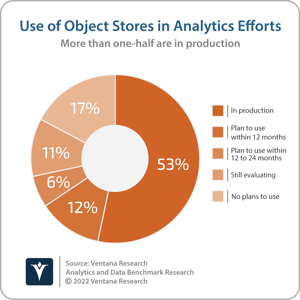
The data lake was first described in 2010 by James Dixon of Pentaho to refer to a single environment where large volumes of data could be stored and processed to be analyzed by multiple users for multiple purposes. Initially based on Apache Hadoop, data lakes are today increasingly based on cloud object storage services. More than one-half (53%) of participants in Ventana Research’s Analytics and Data Benchmark Research currently use object stores in their analytics efforts and an additional 18% plan to do so within the next two years. Data lakes have become an important part of the analytics data estate. In addition to embracing cloud storage, data lakes have also evolved in recent years with the addition of functionality usually found in a data warehouse, including interactive SQL query engines; support for atomic, consistent, isolated and durable (ACID) transactions; updates and deletes; concurrency control; metadata management; and data indexing.
 Dremio has steadily built out the capabilities required to turn a data lake into a data lakehouse. The company started with interactive SQL query engine functionality, now known as Dremio Sonar, which enables interactive analysis of data in a data lake (such as Amazon Web Services S3, Azure Data Lake Storage or Google Cloud Storage) using a variety of BI and visualization tools (such as Tableau, Qlik or Microsoft Power BI). Dremio Sonar is based on the Apache Arrow in-memory data format and offers key features such as Columnar Cloud Cache to take advantage of in-memory data processing using solid-state disk storage and Data Reflections for pre-computation of complex aggregations and other operations. In March, Dremio added the public preview of Dremio Arctic, a metastore service for the Apache Iceberg table format. Dremio Arctic is based on Dremio’s open-source Nessie project, which provides Git-like data branching and version control as well as isolated and consistent data transformations. Dremio Sonar and Dremio Arctic are designed to be used independently of each other: Dremio Sonar can be used with other table formats, such as Delta Lake, while Dremio Arctic can be used with other interactive SQL query engines, including Apache Spark, Apache Flink, Presto and Trino. In combination, however, Sonar and Arctic provide support for SQL Data Manipulation Language (DML) operations, such as inserts, updates and deletes directly on data in cloud storage. Adding this functionality to a data lake makes the resulting data lakehouse a more viable option for running workloads that would traditionally be run on a data warehouse.
Dremio has steadily built out the capabilities required to turn a data lake into a data lakehouse. The company started with interactive SQL query engine functionality, now known as Dremio Sonar, which enables interactive analysis of data in a data lake (such as Amazon Web Services S3, Azure Data Lake Storage or Google Cloud Storage) using a variety of BI and visualization tools (such as Tableau, Qlik or Microsoft Power BI). Dremio Sonar is based on the Apache Arrow in-memory data format and offers key features such as Columnar Cloud Cache to take advantage of in-memory data processing using solid-state disk storage and Data Reflections for pre-computation of complex aggregations and other operations. In March, Dremio added the public preview of Dremio Arctic, a metastore service for the Apache Iceberg table format. Dremio Arctic is based on Dremio’s open-source Nessie project, which provides Git-like data branching and version control as well as isolated and consistent data transformations. Dremio Sonar and Dremio Arctic are designed to be used independently of each other: Dremio Sonar can be used with other table formats, such as Delta Lake, while Dremio Arctic can be used with other interactive SQL query engines, including Apache Spark, Apache Flink, Presto and Trino. In combination, however, Sonar and Arctic provide support for SQL Data Manipulation Language (DML) operations, such as inserts, updates and deletes directly on data in cloud storage. Adding this functionality to a data lake makes the resulting data lakehouse a more viable option for running workloads that would traditionally be run on a data warehouse.
 This does not necessarily displace the need for data warehousing (the other established approach to creating a data platform delivering hydroanalytics is a data warehouse running on, or alongside, a data lake) but I assert that by 2024, more than three-quarters of current data lake adopters will be investing in data lakehouse technologies to improve the business value generated from the accumulated data.
This does not necessarily displace the need for data warehousing (the other established approach to creating a data platform delivering hydroanalytics is a data warehouse running on, or alongside, a data lake) but I assert that by 2024, more than three-quarters of current data lake adopters will be investing in data lakehouse technologies to improve the business value generated from the accumulated data.
There are numerous choices available for organizations looking to enable analysis of data in data lake environments, including stand-alone data warehouse offerings, pre-integrated cloud services and a variety of open-source projects that can be assembled via a do-it-yourself approach. Dremio supports the latter two options with its various open-source projects and the ability to use Sonar and Arctic either independently or in combination. As such, I recommend that any organization considering the data lakehouse approach should evaluate Dremio’s open-source projects and the Dremio Cloud data lakehouse platform when evaluating their options.
Regards,
Matt Aslett
Authors:

Matt Aslett
Director of Research, Analytics and Data
Matt Aslett leads the software research and advisory for Analytics and Data at Ventana Research, now part of ISG, covering software that improves the utilization and value of information. His focus areas of expertise and market coverage include analytics, data intelligence, data operations, data platforms, and streaming and events.








