I recently wrote about the potential benefits of data mesh. As I noted, data mesh is not a product that can be acquired, or even a technical architecture that can be built. It’s an organizational and cultural approach to data ownership, access and governance. While the concept of data mesh is agnostic to the technology used to implement it, technology is clearly an enabler for data mesh. For many organizations, new technological investment and evolution will be required to facilitate adoption of data mesh. Meanwhile, the concept of the data fabric, a technology-driven approach to managing and governing data across distributed environments, is rising in popularity. Although I previously touched on some of the technologies that might be applicable to data mesh, it is worth diving deeper into the data architecture implications of data mesh, and the potential overlap with data fabric.
There are four key principles of data mesh: domain-oriented ownership, data as a product, self-serve data infrastructure and federated governance. The ability to deliver three of those — sharing data as a product across an organization, self-service access and discovery of those data products, and federated data governance — are directly impacted and enabled by technology. Domain-oriented ownership involves giving responsibility to business departments or units to manage the data generated by their applications, and is primarily a cultural and organizational concern. However, it, too, will be influenced by, and have an influence on, technology. Conway's law states that organizations design systems that mirror the organizational structure. As organizational structures adapt to domain-oriented data ownership, so, too, will systems evolve to reflect that.
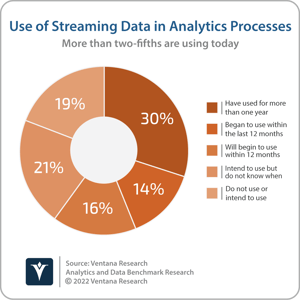 I previously explained that existing investment in data warehouses and data lakes does not need to be abandoned to embrace data mesh. These analytic data platforms can serve a role as data repositories used by individual business domains to store and process domain-oriented data in a data mesh. Investment in new technology may be required to facilitate the sharing, discovery and self-service access to those data products. Many organizations may have already taken the first steps towards embracing suitable technology without necessarily adopting the data mesh approach or terminology. Introducing the concept of the data mesh, Zhamak Dehghani, principal technology consultant at Thoughtworks, stated that “business facts are best presented as business domain events.” Many organizations have already adopted streaming data and event technologies, such as the open source Apache Kafka project, to facilitate and manage the flow of data between applications, systems and business domains. More than two-fifths (44%) of participants to Ventana Research’s Analytics and Data Benchmark Research use streaming data in analytics processes today, and 37% plan to do so. One of the concepts of Kafka, as well as other streaming technologies such as Apache Pulsar, is the publication of events and messages as topics to which consumers subscribe. At the recent Kafka Summit, I spoke to multiple organizations that are already using streaming data and are in the process of adopting data mesh, utilizing the ability to publish and subscribe to topics as a technological enabler for data-as-a-product.
I previously explained that existing investment in data warehouses and data lakes does not need to be abandoned to embrace data mesh. These analytic data platforms can serve a role as data repositories used by individual business domains to store and process domain-oriented data in a data mesh. Investment in new technology may be required to facilitate the sharing, discovery and self-service access to those data products. Many organizations may have already taken the first steps towards embracing suitable technology without necessarily adopting the data mesh approach or terminology. Introducing the concept of the data mesh, Zhamak Dehghani, principal technology consultant at Thoughtworks, stated that “business facts are best presented as business domain events.” Many organizations have already adopted streaming data and event technologies, such as the open source Apache Kafka project, to facilitate and manage the flow of data between applications, systems and business domains. More than two-fifths (44%) of participants to Ventana Research’s Analytics and Data Benchmark Research use streaming data in analytics processes today, and 37% plan to do so. One of the concepts of Kafka, as well as other streaming technologies such as Apache Pulsar, is the publication of events and messages as topics to which consumers subscribe. At the recent Kafka Summit, I spoke to multiple organizations that are already using streaming data and are in the process of adopting data mesh, utilizing the ability to publish and subscribe to topics as a technological enabler for data-as-a-product.
The use of streaming data and event technology is an example of the previously mentioned “push” approach by which data product changes can be distributed as events to subscribing domains as and when they occur. Additionally, as Dehghani explained, “data domains should also provide easily consumable historical snapshots of the source domain datasets.” These could be updated in batch and can be accessed and consumed as required. Multiple technologies could be used to enable the “pull” approach to data access and consumption. In particular, we see that distributed SQL query engines such as Presto or Trino can be used to facilitate and accelerate the sharing of data sets for analysis with a user’s chosen business intelligence tools. Apache Kylin and Apache Pinot provide online analytic processing to pre-aggregate queries that could be served up and consumed as data products.
 While these technologies can help support self-service data access and discovery of data products, self-service data access and discovery also relies on data governance. The data mesh concept is highly reliant on strict enforcement of security and data governance policies as well as interoperability standards. Although responsibility for applying data governance might be distributed to individual business domains, security and privacy enforcement, metadata management will need to be determined at the organizational level and governance policies need to be well codified and automated. Metadata-driven data catalog functionality will be key to delivering on this promise. I assert that through 2024, 7 in ten organizations will use data catalog technologies to improve data governance and accelerate data-driven decision-making.
While these technologies can help support self-service data access and discovery of data products, self-service data access and discovery also relies on data governance. The data mesh concept is highly reliant on strict enforcement of security and data governance policies as well as interoperability standards. Although responsibility for applying data governance might be distributed to individual business domains, security and privacy enforcement, metadata management will need to be determined at the organizational level and governance policies need to be well codified and automated. Metadata-driven data catalog functionality will be key to delivering on this promise. I assert that through 2024, 7 in ten organizations will use data catalog technologies to improve data governance and accelerate data-driven decision-making.
So where does data fabric fit in? While data mesh is a logical data architecture and operating model for distributed data processing, data fabric is a technical approach to automating data management and data governance in a distributed architecture. The two are potentially complementary.
There are various (often highly vendor-centric) definitions of data fabric, but key elements include a data catalog for metadata-driven data governance and self-service, agile data integration. Self-service data access and federated governance are therefore common elements of data fabric and data mesh. While the delivery of data as a product is not integral to data fabric, it could be a facilitator for self-service data discovery and access, and is being added by some data fabric providers. Data fabric products address many of the key requirements for data mesh, albeit without adherence to the importance of domain-oriented data ownership. However, data fabric is agnostic to data ownership rather than opposed to domain-oriented data ownership. It is possible that data fabric could form part of the technological approach adopted by an enterprise to deliver the functionality required for data mesh, along with an organizational shift to domain-oriented data ownership.
There are potential business and technical benefits to be gained from data mesh and data fabric. Disentangling marketing from reality is never easy when it comes to products and services associated with popular and emerging buzzwords. I recommend that organizations approach vendor claims related to both data fabric and data mesh with caution. Focus on defining business and technology goals and seek vendors that can help achieve those goals, regardless of the terminology used to position and market the products and services.
Regards,
Matt Aslett

Matt Aslett
Director of Research, Analytics and Data
Matt Aslett leads the software research and advisory for Analytics and Data at ISG Software Research, covering software that improves the utilization and value of information. His focus areas of expertise and market coverage include analytics, data intelligence, data operations, data platforms, and streaming and events.








