Like every large technology corporation today, IBM faces an innovator’s dilemma in at least some of its business. That phrase comes from Clayton Christensen’s seminal work, The Innovator’s Dilemma, originally published in 1997, which documents the dynamics of disruptive markets and their impacts on organizations. Christensen makes the key point that an innovative company can succeed or fail depending on what it does with the cash generated by continuing operations. In the case of IBM, it puts around US$6 billion a year into research and development; in recent years much of this investment has gone into research on big data and analytics, two of the hottest areas in 21st century business technology. At the company’s recent Information On Demand (IOD) conference in Las Vegas, presenters showed off much of this innovative portfolio.
At the top of the list is Project Neo, which will go into beta release early in 2014. Its purpose to fill the skills gap related to big data analytics, which our benchmark research into big data shows is held back most by lack of knowledgeable staff (79%) and lack of training (77%). The skills situation can be characterized as a three-legged stool of domain knowledge (that is, line-of-business knowledge), statistical knowledge and technological knowledge. With Project Neo, IBM aims to reduce the technological and statistical demands on the domain expert and empower that person to use big data analytics in service of a particular outcome, such as reducing customer churn or presenting the next best offer. In particular, Neo focuses on multiple areas of discovery, which my colleague Mark Smith outlined. Most of the industry discussion about simplifying analytics has revolved around visualization rather than data discovery, which applies analytics that go beyond visualization, or information discovery, which addresses how we find and access information in a highly distributed environment. These areas are the next logical steps after visualization for software vendors to address, and IBM takes them seriously with Neo.
At the heart of Neo are the same capabilities found in IBM’s SPSS  Analytic Catalyst, which won the 2013 Ventana Research Innovation Award for analytics and which I wrote about. It also includes IBM’s BLU acceleration against the DB2 database, an in-memory optimization technique, which I have discussed as well, that provides access to the analysis of large data sets. The company’s Vivisimo acquisition, which is now called InfoSphere Data Explorer, adds information discovery capabilities. Finally, the Rapid Adaptive Visualization Engine (RAVE), which is IBM’s visualization approach across its portfolio, is layered on top for fast, extensible visualizations. Neo itself is a work in progress currently offered only over the cloud and back-ended by the DB2 database. However, following the acquisition earlier this year of SoftLayer, which provides a cloud infrastructure platform. I would expect to also have IBM make Neo to allow it to access more sources than just loaded data into IBM DB2.
Analytic Catalyst, which won the 2013 Ventana Research Innovation Award for analytics and which I wrote about. It also includes IBM’s BLU acceleration against the DB2 database, an in-memory optimization technique, which I have discussed as well, that provides access to the analysis of large data sets. The company’s Vivisimo acquisition, which is now called InfoSphere Data Explorer, adds information discovery capabilities. Finally, the Rapid Adaptive Visualization Engine (RAVE), which is IBM’s visualization approach across its portfolio, is layered on top for fast, extensible visualizations. Neo itself is a work in progress currently offered only over the cloud and back-ended by the DB2 database. However, following the acquisition earlier this year of SoftLayer, which provides a cloud infrastructure platform. I would expect to also have IBM make Neo to allow it to access more sources than just loaded data into IBM DB2.
IBM also recently started shipping SPSS Modeler 16.0. IBM bought SPSS in 2009 and has invested in Modeler heavily. Modeler 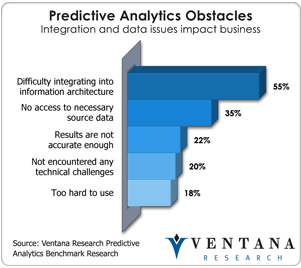 (formerly SPSS Clementine) is an analytic workflow tool akin to others in the market such as SAS Enterprise Miner, Alteryx and more recent entries such as SAP Lumira. SPSS Modeler enables analysts at multiple levels to interact on analytics and do both data exploration and predictive analytics. Analysts can move data from multiple sources and integrate it into one analytic workflow. These are critical capabilities as our predictive analytics benchmark research shows: The biggest challenges to predictive analytics are architectural integration (for 55% of organizations) and lack of access to necessary source data (35%).
(formerly SPSS Clementine) is an analytic workflow tool akin to others in the market such as SAS Enterprise Miner, Alteryx and more recent entries such as SAP Lumira. SPSS Modeler enables analysts at multiple levels to interact on analytics and do both data exploration and predictive analytics. Analysts can move data from multiple sources and integrate it into one analytic workflow. These are critical capabilities as our predictive analytics benchmark research shows: The biggest challenges to predictive analytics are architectural integration (for 55% of organizations) and lack of access to necessary source data (35%).
IBM has made SPSS the centerpiece of its analytic portfolio and offers it at three levels, Professional, Premium and Gold. With the top-level Gold edition, Modeler 16.0 includes capabilities that are ahead of the market: run-time integration with InfoSphere Streams (IBM’s complex event processing product), IBM’s Analytics Decision Management (ADM) and the information optimization capabilities of G2, a skunks-works project by led by Jeff Jonas, chief scientist of IBM’s Entity Analytics Group.
Integration with InfoSphere Streams that won a Ventana Research Technology Innovation award in 2013 enables event processing to occur in an analytic workflow within Modeler. This is a particularly compelling capability as the so-called “Internet of things” begins to evolve and the ability to correlate multiple events in real time becomes crucial. In such real-time environments, often quantified in milliseconds, events cannot be pushed back into a database and wait to be analyzed.
Decision management is another part of SPSS Modeler. Once models are built, users need to deploy them, which often entails steps such as integrating with rules and optimizing parameters. In a next best offer situation in a retail banking environment, for instance, a potential customer may score highly on propensity want to take out a mortgage and buy a house, but other information shows that the person would not qualify for the loan. In this case, the model itself would suggest telling the customer about mortgage offers, but the rules engine would override it and find another offer to discuss. In addition, there are times when optimization exercises are needed such as Monte Carlo simulations to help to figure out parameters such as risk using “what-if” modelling. In many situations, to gain competitive advantage, all of these capabilities must be rolled into a production environment where individual records are scored in real time against the organization’s database and integrated with the front-end system such as a call center application. The net capability that IBM’s ADM brings is the ability to deploy analytical models into the business without consuming significant resources.
G2 is a part of Modeler and developed in IBM’s Entity Analytics Group. The group is garnering a lot of attention both internally and externally for its work around “entity analytics” – the idea that each information entity has characteristics that are revealed only in contextual information – charting innovative methods in the areas of data integration and privacy. In the context of Modeler this has important implications for bringing together disparate data sources that naturally link together but otherwise would be treated separately. A core example is that an individual may have multiple email addresses in different databases, has changed addresses or changed names perhaps due to a new marital status. Through machine-learning processes and analysis of the surrounding data, G2 can match records and attach them with some certainty to one individual. The system also strips out personally identifiable information (PII) to meet privacy and compliance standards. Such capabilities are critical for business as our latest benchmark research on information optimization shows that two in five organizations have more than 10 different data sources that they need to integrate and that the ability to simplify access to these systems is important to virtually all organizations (97%).
With the above capabilities, SPSS Modeler Gold edition achieves market differentiation, but IBM still needs to show the advantage of base editions such as Modeler Professional. The marketing issue for SPSS Modeler is that it is considered a luxury car in a market being infiltrated by compacts and kit cars. In the latter case there is the R programming language, which is open-source and ostensibly free, but the challenge here is that companies need R programmers to run everything. SPSS Modeler and other such visually oriented tools (many of which integrate with open source R) allow easier collaboration on analytics, and ultimately the path to value is shorter. Even at its base level Modeler is an easy-to-use and capable statistical analysis tool that allows for collaborative workgroups and is more mature than many others in the market.
Companies must consider predictive analytics capabilities or 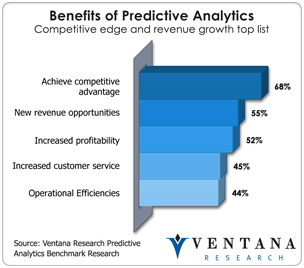 risk being left behind. Our research into predictive analytics shows that two-thirds of companies see predictive analytics as providing competitive advantage (68%) and particularly important in revenue-generating functions such as marketing (for 70%) and forecasting (72%). Companies currently looking into discovery analytics may want to try Neo, which will be available in beta in early 2014. Those interested in predictive analytics should consider the different levels of SPSS 16.0 as well as IBM’s flagship Signature Solutions, which I have covered. IBM has documented use cases that can give users guidance in terms of leading-edge deployment patterns and leveraging analytics for competitive advantage. If you have not taken a look at the depth of the analytic technology portfolio at IBM, I would make sure to do so, as you might miss some fundamental advancements to the processing of data and analytics to provide the valuable insights required to operate effectively in the global marketplace.
risk being left behind. Our research into predictive analytics shows that two-thirds of companies see predictive analytics as providing competitive advantage (68%) and particularly important in revenue-generating functions such as marketing (for 70%) and forecasting (72%). Companies currently looking into discovery analytics may want to try Neo, which will be available in beta in early 2014. Those interested in predictive analytics should consider the different levels of SPSS 16.0 as well as IBM’s flagship Signature Solutions, which I have covered. IBM has documented use cases that can give users guidance in terms of leading-edge deployment patterns and leveraging analytics for competitive advantage. If you have not taken a look at the depth of the analytic technology portfolio at IBM, I would make sure to do so, as you might miss some fundamental advancements to the processing of data and analytics to provide the valuable insights required to operate effectively in the global marketplace.
Regards,
Tony Cosentino
VP and Research Director
ISG Software Research
ISG Software Research is the most authoritative and respected market research and advisory services firm focused on improving business outcomes through optimal use of people, processes, information and technology. Since our beginning, our goal has been to provide insight and expert guidance on mainstream and disruptive technologies. In short, we want to help you become smarter and find the most relevant technology to accelerate your organization's goals.








