
I was recently asked to identify key modern data architecture trends. Data architectures have changed significantly to accommodate larger volumes of data as well as new types of data such as streaming and unstructured data. Here are some of the trends I see continuing to impact data architectures.
Scalability and Elasticity
The economics of data and analytics have changed, making it much less expensive and more valuable to work with large amounts of data. The costs of computing and storage have declined so dramatically that organizations can save and analyze virtually all the information they collect. The reasons for this change go beyond Moore’s Law of increasing computing power. These advances in large part are due to scale-out, distributed systems.
With the decline in computing costs and increase in computing power, organizations are now able to perform more sophisticated analyses such as artificial intelligence (AI) and machine learning (ML), which increase the value of data. To predict fraud or mechanical failure, or a customer’s propensity to respond to a marketing campaign, an organization needs many observations to determine the patterns behind those occurrences and accurately predict behavior.
The benefits of these analyses 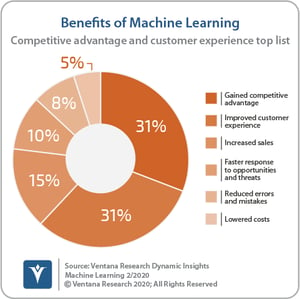 are significant. Our Dynamic Insights research on machine learning finds that the most common benefit organizations report is a better competitive advantage. Organizations also report lowering costs, improving customer experiences, responding faster to opportunities in the market and increasing sales.
are significant. Our Dynamic Insights research on machine learning finds that the most common benefit organizations report is a better competitive advantage. Organizations also report lowering costs, improving customer experiences, responding faster to opportunities in the market and increasing sales.
Scalability and elasticity are critical because these analyses require that organizations be able to work with large amounts of data — as large as necessary — in a cost-effective way. An organization must be able to scale up, but it also needs an elastic data architecture to reduce the resources consumed and operating costs when workloads are lighter.
Streaming Data
We are in the midst of a paradigm shift in the world of data, a shift from data at rest to data in motion. By data at rest, I mean traditional databases that store batches of information — for example, from point of sale terminals at the end of the day. However, sales and the corresponding data don’t naturally occur in batches. Data occurs continuously, but we have been limited by technology to process it as a series of loads.
Streaming data is not entirely new. We’ve always had little bits of streaming data, but it was the exception rather than the rule. It existed in pockets within the organization and required specialized, separate technology. For example, for decades capital markets specialists have had technology to process trade data from securities exchanges. But we see streaming data going mainstream, driven largely by open source technologies such as Kafka, Spark, Flink and others.
That doesn’t mean historical databases go away. After an organization processes the streams of data, it will save much or all of it in historical databases. Organizations can use this historical data to create models that can react and respond to data as it streams through the system. Once those models are developed, they are deployed into a streaming data architecture to process data in-line as it occurs. The whole idea is to be able to react in the moment and change the outcome while there’s still a window of opportunity.
Cloud-Based Data Warehouses and Data Lakes
Hadoop, another open source technology, was one of the key drivers of the move to big data. It was more scalable than alternatives that existed at the time, less expensive and more flexible in terms of the data structures and analytics it supported. But Hadoop is complicated. A Hadoop installation has many moving parts, which our research shows requires specialized skills and lots of resources. Organizations have sought ways to reduce this complexity, one being a move to the cloud. Our benchmark research on Data and Analytics in the Cloud shows that one-fourth of organizations already have more than half of their data in the cloud and the vast majority (86%) expect they will have most of their data in the cloud at some point in the future. The research also finds that one-third of organizations have their primary data lake platform in the cloud.
Not only is data moving to the cloud, but analytics are as well. About half of the participants in our research said they already perform analytics in the cloud and nearly all participants said they expect to in the future. Our research also shows that those organizations using the cloud report better outcomes than those that don’t.
Unstructured Data
Unstructured data and streaming data are two of the main sources of big data. Unstructured data includes text, images, audio, video and many types of log files, however, the term “unstructured data” is a misnomer. The data is structured; it's just not structured into rows and columns that fit neatly into a relational table like much of the other information organizations process.
A modern data architecture must not only provide a way to manage this type of data, but it must also provide a mechanism to analyze this information. Generally, this involves AI and ML. There's so much information, organizations need an algorithmic approach to determine the patterns in the data. Organizations participating in our research report that the most important source of external data for their AI and ML efforts is social media, an unstructured data source.
it must also provide a mechanism to analyze this information. Generally, this involves AI and ML. There's so much information, organizations need an algorithmic approach to determine the patterns in the data. Organizations participating in our research report that the most important source of external data for their AI and ML efforts is social media, an unstructured data source.
The other thing that we see happening is that conversational computing is becoming more common. Whether through voice-based interfaces or text-based chat bots, interacting with customers electronically using natural language will improve the customer experience as the technology improves. These natural language exchanges create another large stream of unstructured information that can be used to improve many aspects of the customer experience.
Data Quality and Governance
While not strictly a data architecture trend, modern data architectures need to incorporate provisions for appropriate data quality and governance. As indicated above, AI and ML are critical parts of analyzing modern data. Our research shows that the most common challenge organizations report in applying these technologies is accessing and preparing data. Drilling down into the tasks involved in data preparation, more than half of participants cited the need to perform data quality activities. Our research also finds that data quality is one of the most time-consuming parts of data preparation. It’s important to get data quality right. High-quality results aren’t possible without high-quality data, nor is confidence in the data across the enterprise.
Furthermore, AI can pose particular challenges to data governance efforts. The volume and variety of data involved along with frequent updates complicate governance. In addition, much of this data and many of these analyses include personally identifiable information. Obfuscating and masking the information is a critical part of data governance processes. But perhaps the most complicated governance issue is the temporal nature of AI and ML models. In extreme scenarios, a model may only exist for minutes — for example, in online advertising. As various news hits the wires, different topics increase or decrease in popularity and the advertisements and offers will change, sometimes requiring frequent and rapid updates to the underlying models. Organizations must not only govern the data, but also must consider the models they use. These are complicated issues that are not fully resolved yet.
As you consider a modernization of your data architecture, it’s important to keep these five trends in mind. I urge you to understand and incorporate both scalability and elasticity. Seek to accommodate streaming data sources and examine the way cloud-based data warehouses and data lakes can potentially enhance your data processes. Embrace unstructured data as an important source of insight. And provide a framework to ensure the appropriate data quality and governance of both your data and the AI and ML models you apply to that data.
Regards,
Dave Menninger
Authors:

David Menninger
Executive Director, Technology Research
David Menninger leads technology software research and advisory for Ventana Research, now part of ISG. Building on over three decades of enterprise software leadership experience, he guides the team responsible for a wide range of technology-focused data and analytics topics, including AI for IT and AI-infused software.








